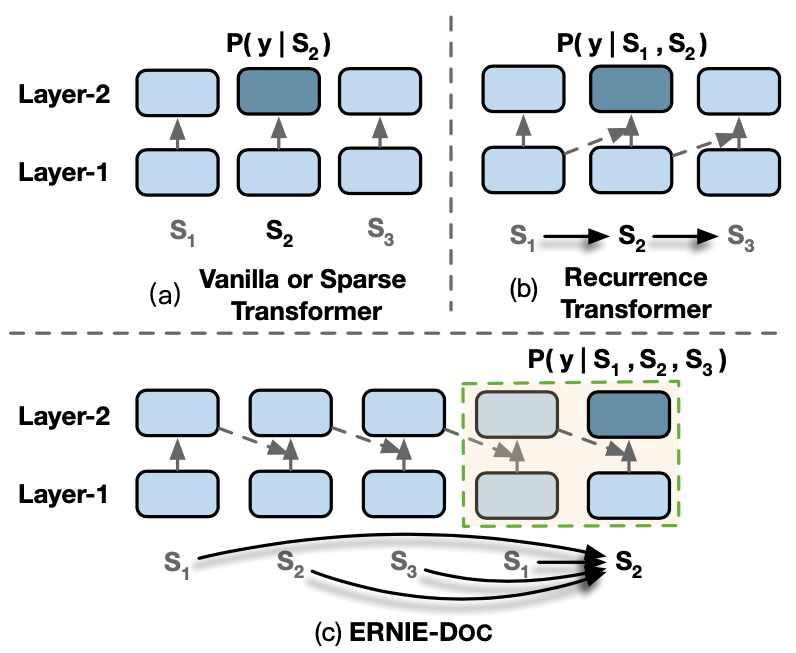
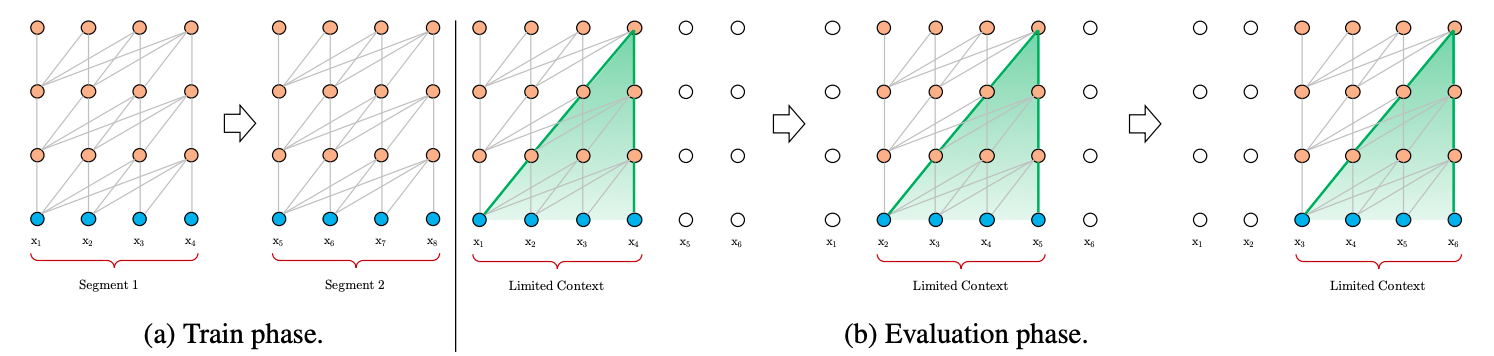
经典的Transformer在处理数据时,会将文本数据按照固定长度进行截断,这个看起来比较”武断”的操作会造成上下文碎片化以及无法建模更长的...
本篇文章译自英文文档 Compile TFLite Models 作者是 FrozenGene (Zhao Wu) · GitHub更多 TVM 中文文档可访问 →Apache TVM 是一个端到端...
ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方...
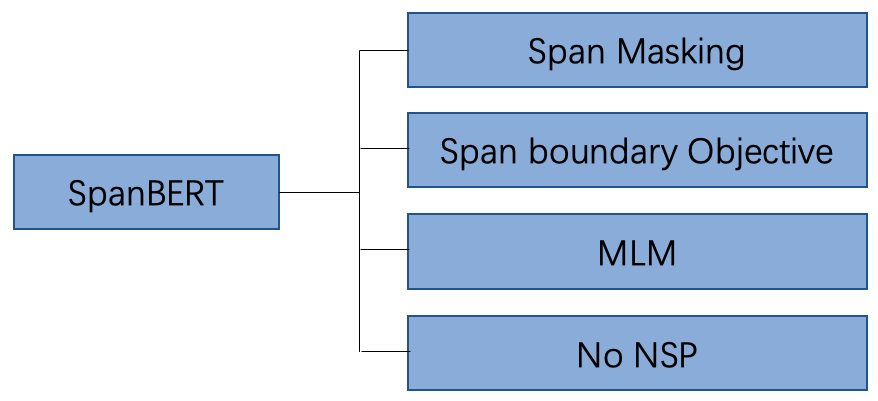
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解1.SpanBERT: Improving ...
自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序...
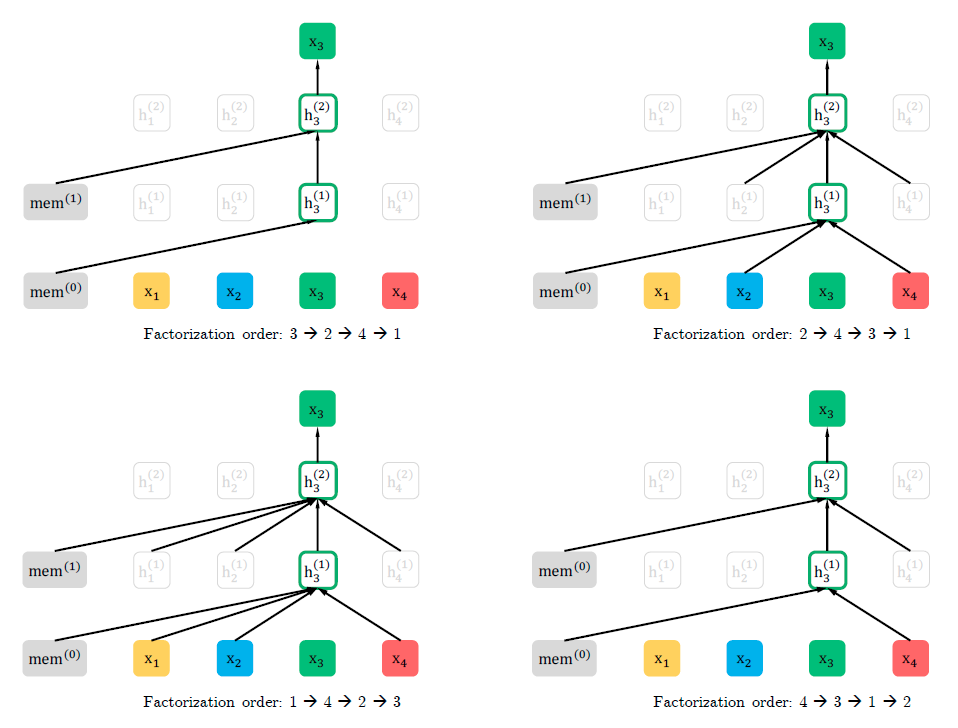
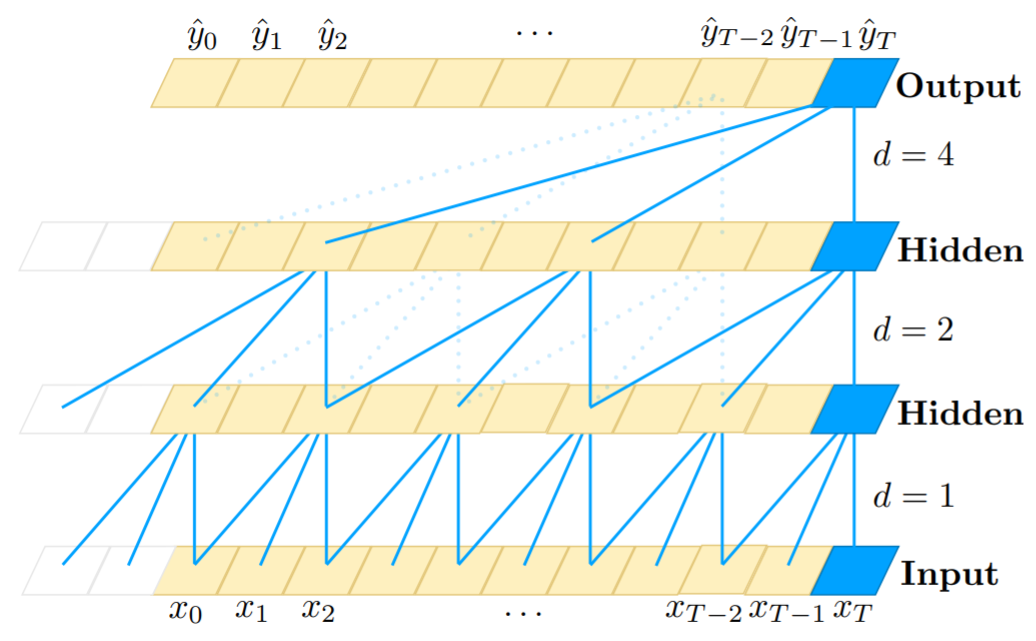
在正式讨论 Transformer-XL 之前,我们先来看看经典的 Transformer(后文称 Vanilla Transformer)是如何处理数据和训练评估模型的,如...
时间序列数据是按一定时间间隔记录的一系列观测结果。它经常在金融、天气预报、股票市场分析等各个领域遇到。分析时间序列数据可以提供...
本文将详细解释XGBoost中十个最常用超参数的介绍,功能和值范围,及如何使用Optuna进行超参数调优。
从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作...

目前看到的最通俗易懂、由浅入深的图解机器学习和GPT原理的系列文章,这是第一篇,由我和 GPT-4共同翻译完成,分享给大家。原作者:@Jay...
内容一览:20 世纪以来,干细胞与再生医学技术一直是国际生物医学领域的热点前沿之一。现如今,研究人员已开始探索将干细胞转变为特定类...

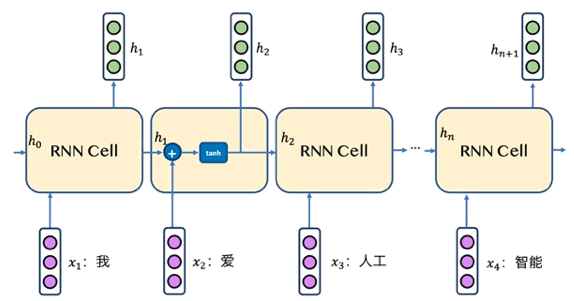
生活中,我们经常会遇到或者使用一些时序信号,比如自然语言语音,自然语言文本。以自然语言文本为例,完整的一句话中各个字符之间是有...
内容一览:随着人口老龄化程度不断加剧,痴呆症已经成为公共健康问题。目前医学界治疗该病还只能通过药物缓解,尚未发现治愈的有效方法...

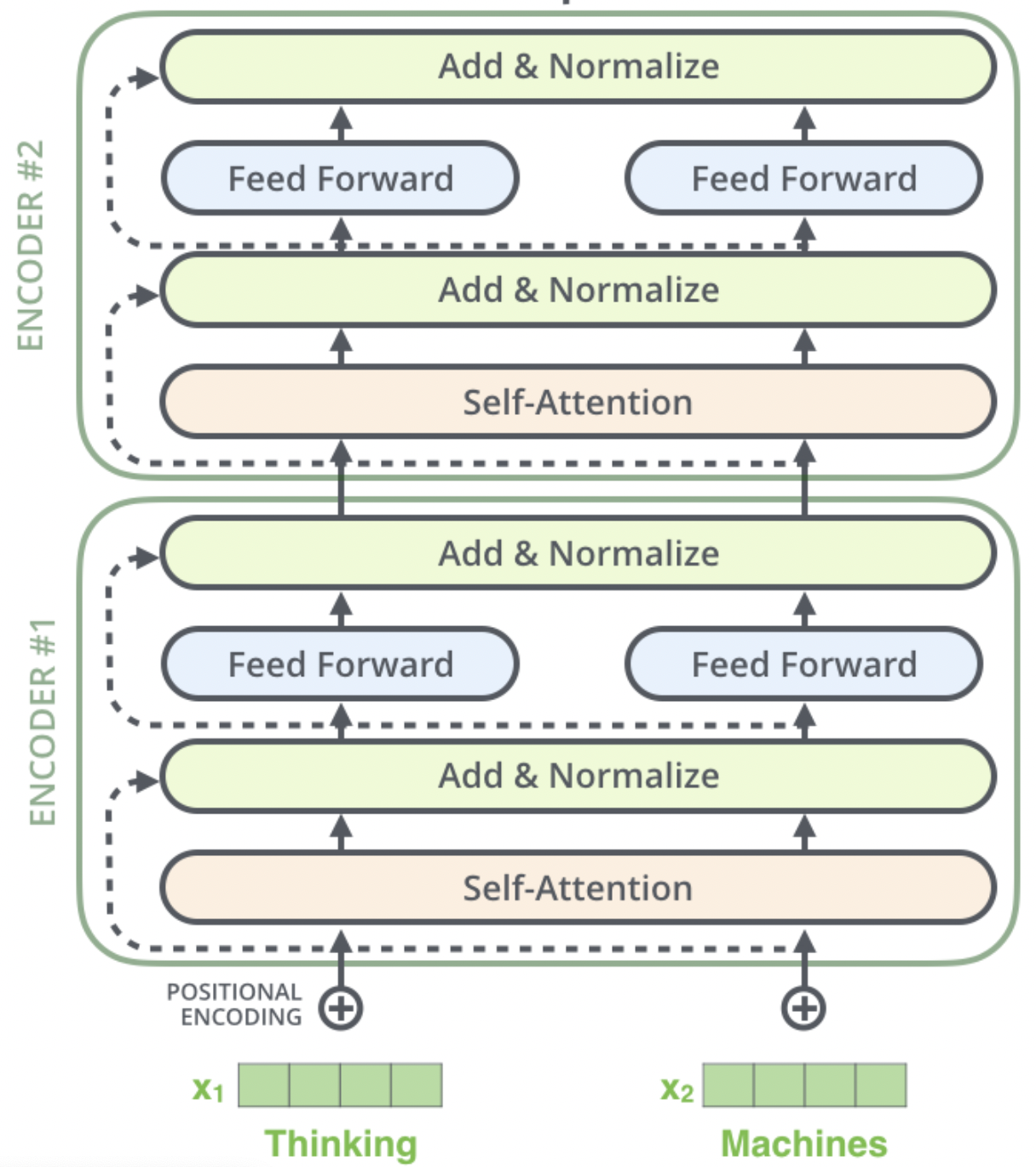
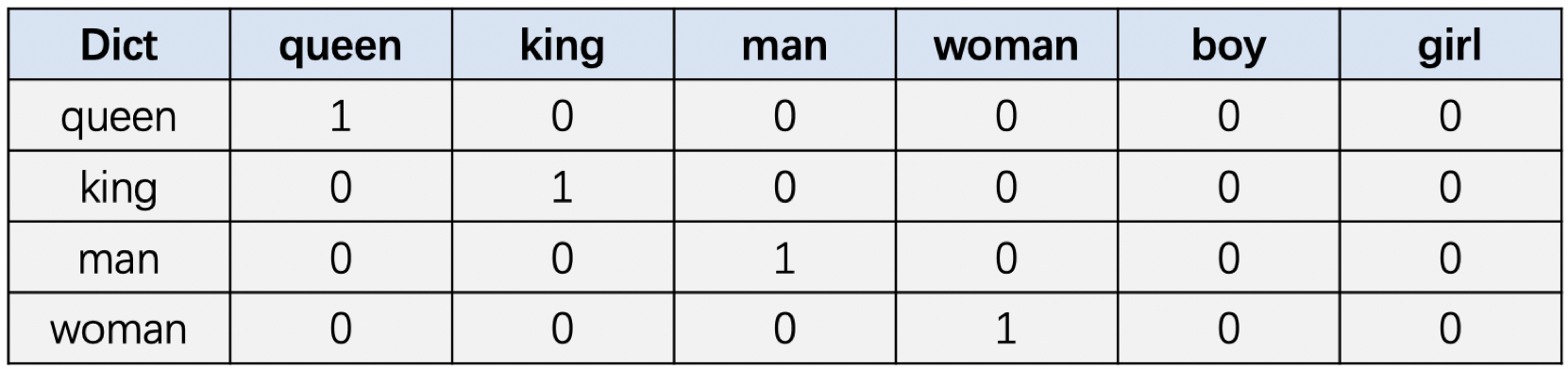
在NLP领域,自然语言通常是指以文本的形式存在,但是计算无法对这些文本数据进行计算,通常需要将这些文本数据转换为一系列的数值进行计...
变分量子分类器(Variational Quantum Classifier,简称VQC)是一种利用量子计算技术进行分类任务的机器学习算法。它属于量子机器学习算...
图像级监督的弱监督语义分割(WSSS)由于其标注成本较像素级标注低而受到越来越多的关注。大多数现有方法依赖于类激活图(Class Activation...

$1\times{1}$卷积,与标准卷积完全一样,唯一的特殊点在于卷积核的尺寸是$1\times{1}$,也就是不去考虑输入数据局部信息之间的关系,而...

随着AIGC概念在全球内外的火热,国内厂商也开始注重自身AI技术能力的开发,在人工智能技术上投入了大量算力、算法及数据的资源。

本次任务我们将学习来自TOP选手“swg-lhl”的冠军建模方案,该方案中采用的模型是TCNN+RNN。
数据分析是解决一个数据挖掘任务的重要一环,通过数据分析,我们可以了解标签的分布、数据中存在的缺失值和异常值、特征与标签之间的相...








