注意力机制的掩码允许我们发送不同长度的批次数据一次性的发送到transformer中。在代码中是通过将所有序列填充到相同的长度,然后使用“a...
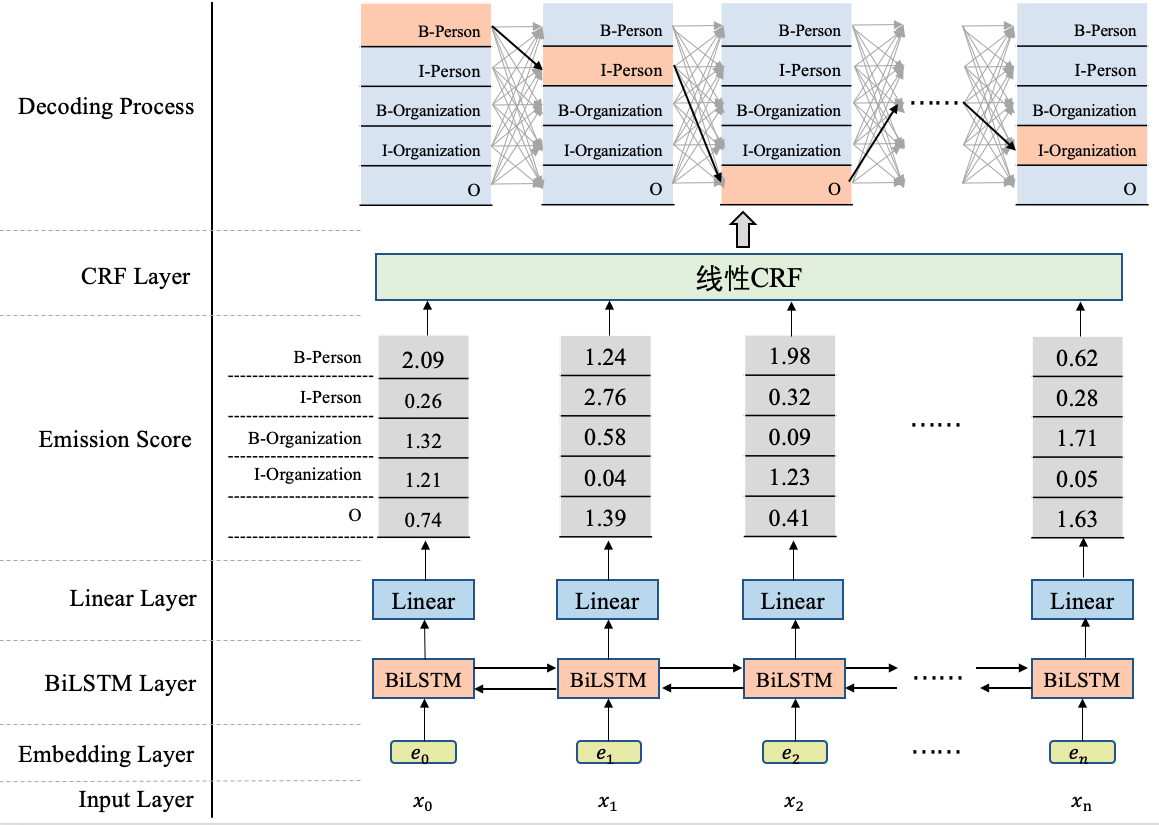
命名实体识别(Named Entity Recoginition, NER)旨在将一串文本中的实体识别出来,并标注出它所指代的类型,比如人名、地名等等。具体...
在Pandas 2.0发布以后,我们发布过一些评测的文章,这次我们看看,除了Pandas以外,常用的两个都是为了大数据处理的并行数据框架的对比...
本文提供了使用Streamlit和OpenAI创建的视频摘要应用程序的概述。该程序为视频的每个片段创建简洁的摘要,并总结视频的完整内容。
相较于VGG的19层和GoogLeNet的22层,ResNet可以提供18、34、50、101、152甚至更多层的网络,同时获得更好的精度。但是为什么要使用更深...

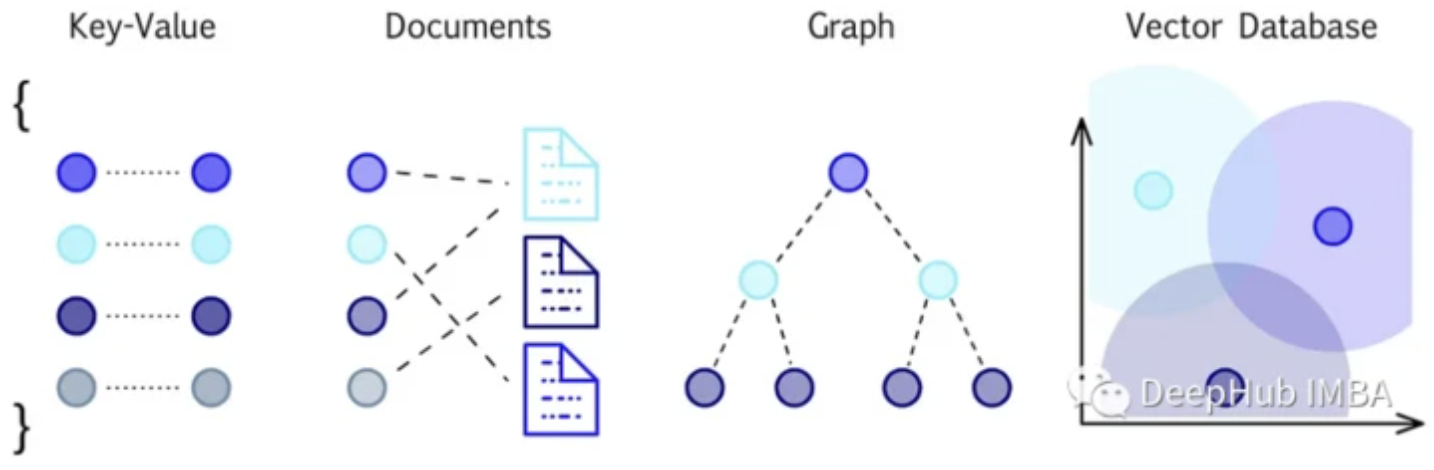
矢量数据库是为实现高维矢量数据的高效存储、检索和相似性搜索而设计的。使用一种称为嵌入的过程,将向量数据表示为一个连续的、有意义...
这是新加坡国立大学在2022 aaai发布的一篇论文。WideNet是一种参数有效的框架,它的方向是更宽而不是更深。通过混合专家(MoE)代替前馈网...
18大数据挖掘的经典算法以及代码实现,涉及到了决策分类,聚类,链接挖掘,关联挖掘,模式挖掘等等方面,后面都是相应算法的博文链接,希...

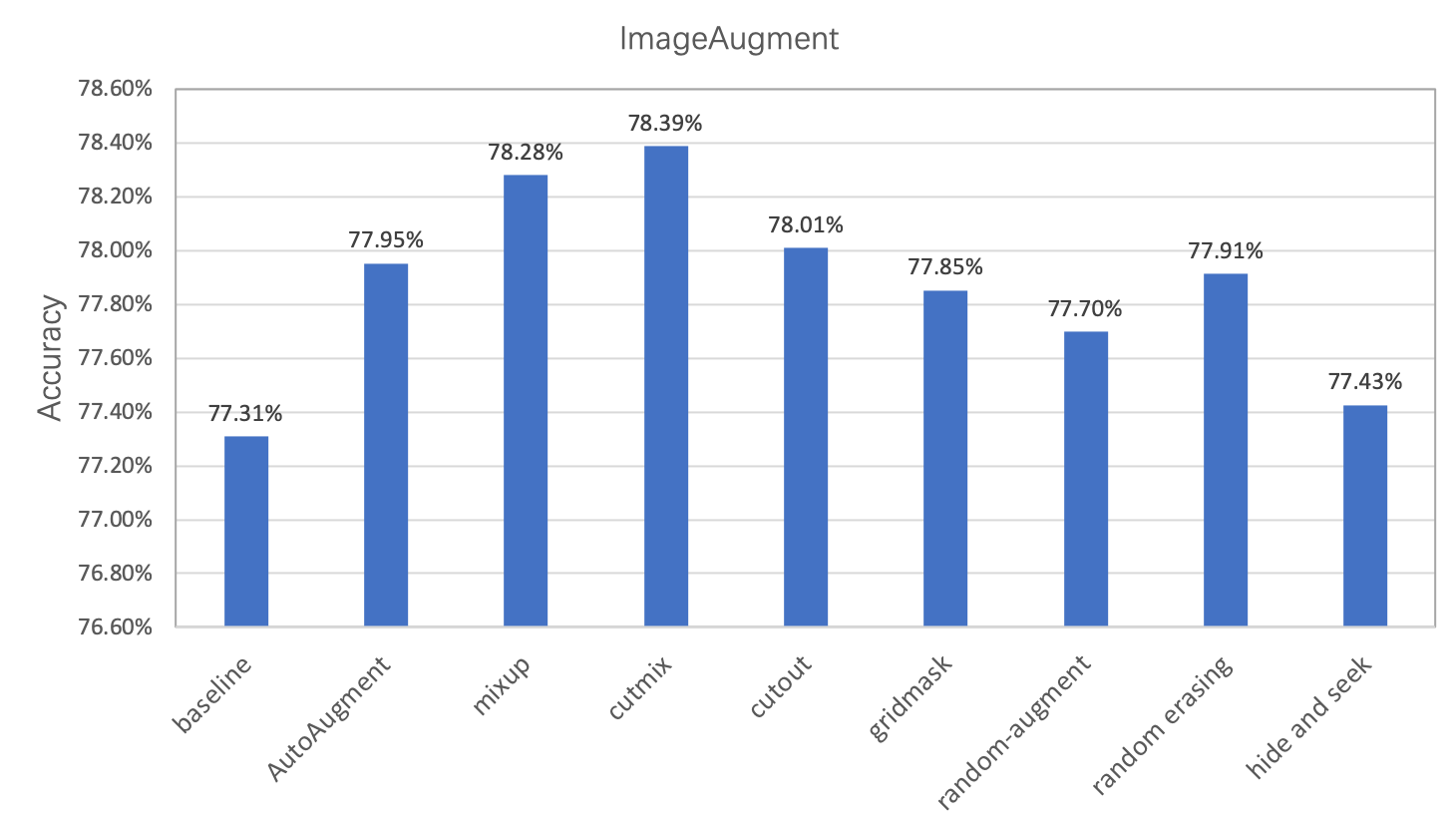
在图像分类任务中,图像数据的增广是一种常用的正则化方法,主要用于增加训练数据集,让数据集尽可能的多样化,使得训练的模型具有更强...
人工智能领域:面试常见问题超全(深度学习基础、卷积模型、对抗神经网络、预训练模型、计算机视觉、自然语言处理、推荐系统、模型压缩...
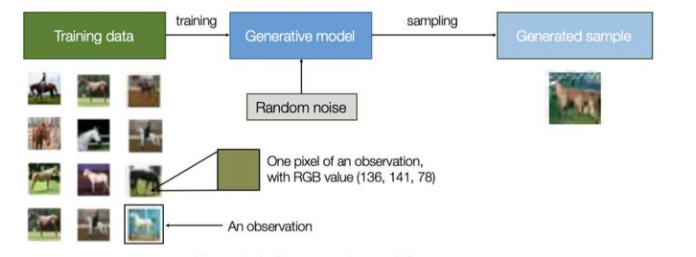
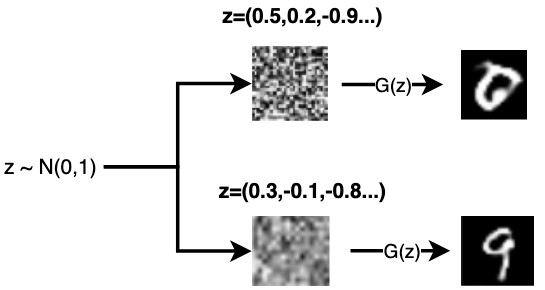
所谓生成模型,就是指可以描述成一个生成数据的模型,属于一种概率模型。维基百科上对其的定义是:在概率统计理论中, 生成模型是指能...
这时一篇2015年的论文,但是他却是最早提出在语义分割中使用弱监督和半监督的方法,SAM的火爆证明了弱监督和半监督的学习方法也可以用在...
OpenAI Gym中其实集成了很多强化学习环境,足够大家学习了,但是在做强化学习的应用中免不了要自己创建环境,比如在本项目中其实不太好...
内容一览: 基因渐渗与葡萄的驯化、遗传改良密切相关。先前研究揭示了欧洲栽培葡萄中,野生葡萄基因渐渗的基因组信号,但尚未深入研究这...

本篇文章译自英文文档 Compile CoreML Models 作者是 Joshua Z. Zhang,Kazutaka Morita,Zhao Wu更多 TVM 中文文档可访问 →Apache TVM ...
理性这个关键字,因为它是博弈论的基础。我们可以简单地把理性称为一种理解,即每个行为人都知道所有其他行为人都和他/她一样理性,拥有...
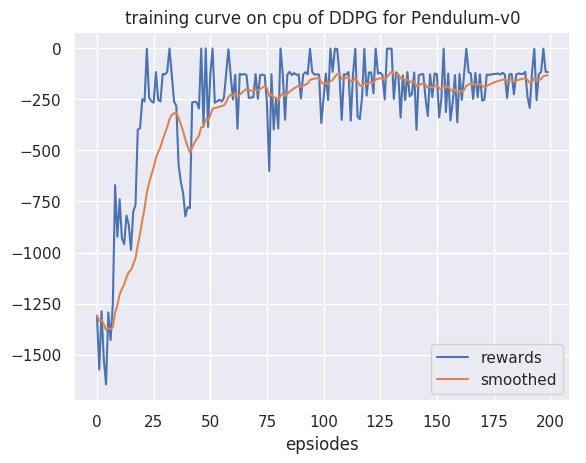
深度Q网络(deep Q-network,DQN):基于深度学习的Q学习算法,其结合了价值函数近似(value function approximation)与神经网络技术,...
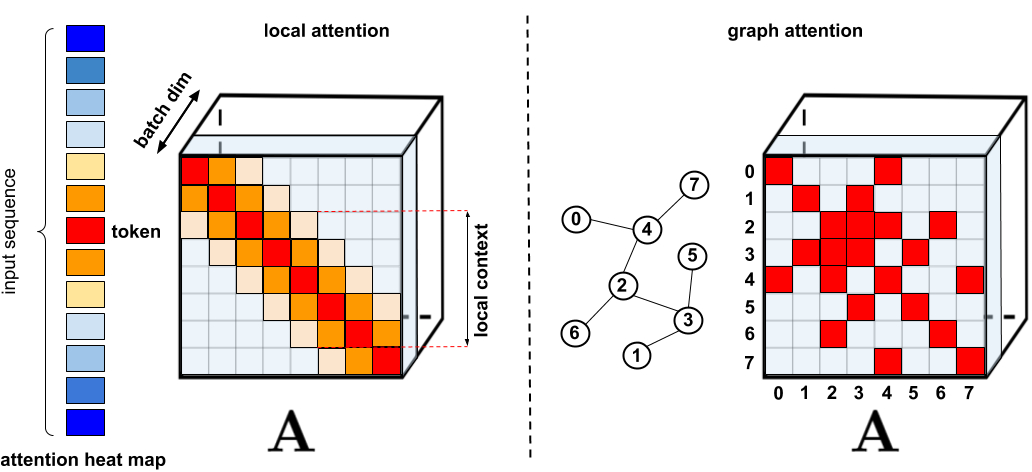
基于Transformer模型在众多领域已取得卓越成果,包括自然语言、图像甚至是音乐。然而,Transformer架构一直以来为人所诟病的是其注意力...
内容一览: 药物喷墨打印是一种高度灵活和智能化的制药方式。据相关报告统计,该领域市场规模将在不久的未来呈现指数级增长。过往,筛选...

内容一览:「2023 Meet TVM·北京站」于 6 月 17 日在中关村车库咖啡顺利举办,现场吸引了来自企业和高校的 150 余名参与者,大家进行了...







