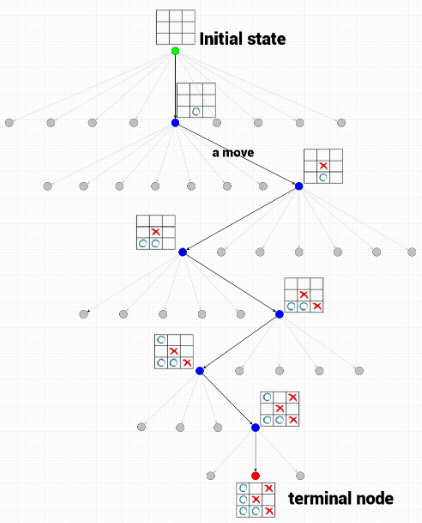
上节聊完了这个强化学习从直观上的一些理解。以及它和其他的机器学习方法的一些异同点。这一节来唠唠强化学习中的一些基本...
在19年4月,有写过一篇强化学习的入门直观简介。强化学习通俗入门简介(一)。感兴趣的可以看一下,如果知道一些基本概念的话...
本文将之前的一篇基于强化学习的倒立摆控制策略Matlab实现文章再次进行了扩充。
什么是强化学习(Reinforcement Learning)?他和监督学习有什么区别?这里我将从监督学习切入,来用几篇文章解释清楚强化学...

论文题目:Addressing Function Approximation Error in Actor-Critic Methods

论文题目:Continuous Control With Deep Reinforcement Learning

stochastic policy的方法由于含有部分随机,所以效率不高,方差大,采用deterministic policy方法比stochastic policy的采...
本文是自己的TRPO算法学习笔记,在数学原理推导核心部分附有自己的理解与解释。整篇文章逻辑清晰,思路顺畅。有想推导的同...
论文题目:Asynchronous Methods for Deep Reinforcement Learning
Experience replay能够让强化学习去考虑过去的一些经验,在【1】这篇文章之前通常采用随机采样的方式在记忆库中采样。但是...

本文作者来自于宾夕法尼亚州立大学,提出了一种使用深度强化学习解决交通问题的方法。报道:深度强化学习实验室 作者:DeepRL
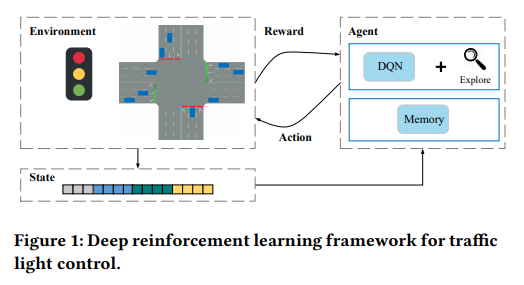
深度强化学习是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了...

这次我们在上次的例子中在提升一下,这次我们选用条件生成对抗模型(Conditional Generative Adversarial Networks)来生成数字图片。

RLax(发音为“ relax”)是建立在JAX之上的库,它公开了用于实施强化学习智能体的有用构建块。。报道:深度强化学习实验室作者:DeepRL ...

本文主要介绍深度强化学习在任务型对话上的应用,两者的结合点主要是将深度强化学习应用于任务型对话的策略学习上来源:腾讯技术工程微信号
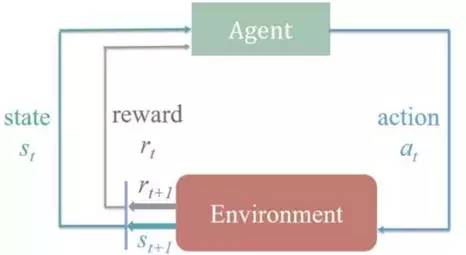
专栏中《零神经网络实战》系列持续更新介绍神经元怎么工作,最后使用python从0到1不调用任何依赖神经网络框架(不使用tensorflow等框架)...
本文对强化学习的相关资料从视频,书籍,PPT等做了非常全面的整理,必须关注。报道:深度强化学习实验室作者:岳龙飞 编辑:DeepRL
当我们设计了一个强化学习算法之后,我们如何来验证算法的好坏呢?就像数据集一样,我们需要一个公认的平台来衡量这个算法...

我的微信公众号名称:深度学习与先进智能决策微信公众号ID:MultiAgent1024公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相...

本文是对Monte Carlo Tree Search – beginners guide这篇文章的文章大体翻译,以及对其代码的解释。分为两篇【详细原理】和...