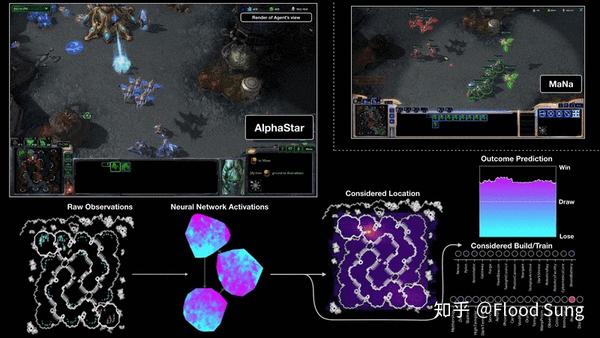
近几年来,以DeepMind和OpenAI为首的AI明星公司基于深度强化学习创造了前所未有的突破,包括AlphaGo,AlphaStar,OpenAI Five, OpenAI R...
在投资界活跃着一批乘风破浪的姐姐们,江湖人敬称一声“花姐”的华旦天使投资创始人张洁是个中代表:言谈飒爽,举止利落,洞察力十足。技...

不知不觉中求职季已经进行了很长时间,算法岗位的招聘可以说是非常火爆,但目前强化学习的面试题目相对来说比较少,本文整理了大约50多...

作者:SFXiang首发:AI算法修炼营这是目前为止最全面、最科学的有关深度学习SLAM方法的总结。论文地址: [链接]代码地址: [链接]基于深...

【高级强化学习课程+项目】Advanced Topics in Deep Reinforcement learning开课啦!

Huskarl是一种基于TensorFlow 2.0构建的深度强化学习的框架,其专注于模块化和快速原型设计。设计中尽可能使用了tf.keras API以实现简洁...
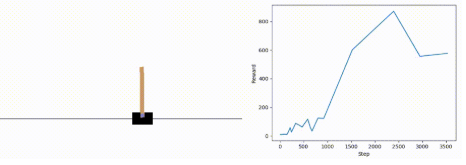
强化学习实验中的绘图技巧-使用seaborn绘制paper中的图片,使用seaborn绘制折线图时参数数据可以传递ndarray或者pandas,不同的源数据对...
OpenAI,由诸多硅谷大亨联合建立的人工智能非营利组织。2015年马斯克与其他硅谷科技大亨进行连续对话后,决定共同创建OpenAI,希望能够...
ICML 2020放榜了。入选论文创新高,共有1088篇论文突出重围。然而,接收率却是一年比一年低,这次仅为21.8%(去年为22.6%,前年为24.9%...
报道:深度强化学习实验室资料来源:Google Research 编辑:DeepRL本框架是Google发布于ICLR2020顶会上,这两天发布于Google Blog上 论...

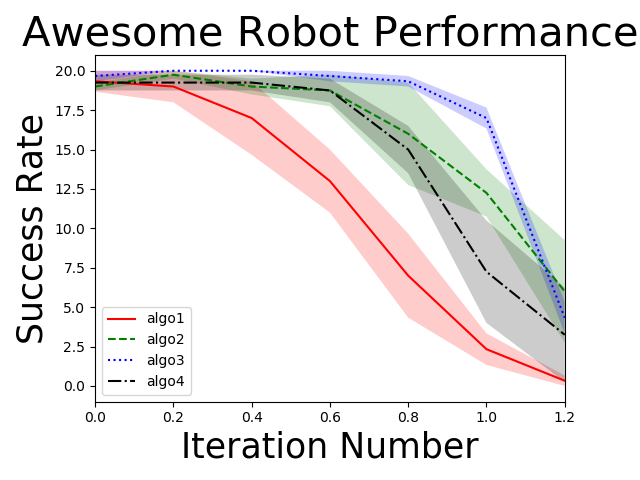
许多研究人员认为,基于模型的强化学习(MBRL)比无模型的强化学习(MFRL)具有更高的样本效率。但是,从根本上讲,这种说法是错误的。...
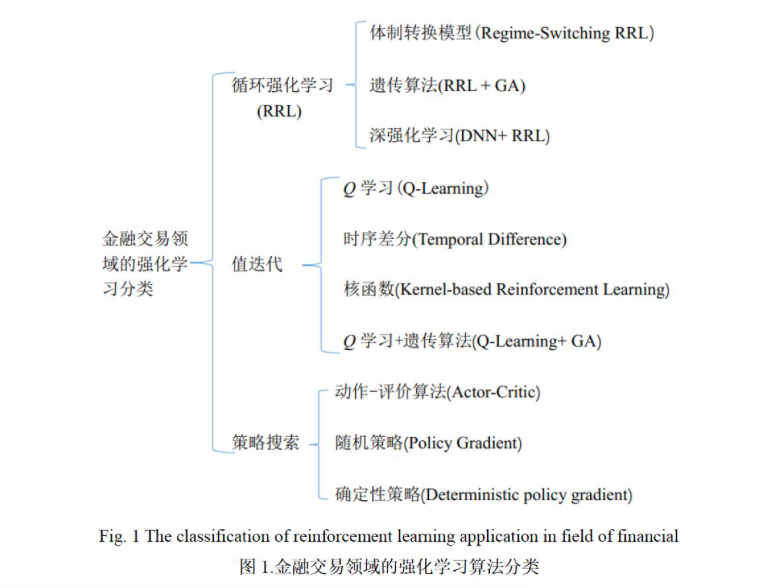
近年来,强化学习在电子游戏、棋类、决策控制领域取得了巨大进展,也带动着金融交易系统的迅速发展,金融交易问题已经成为强化学习领域...
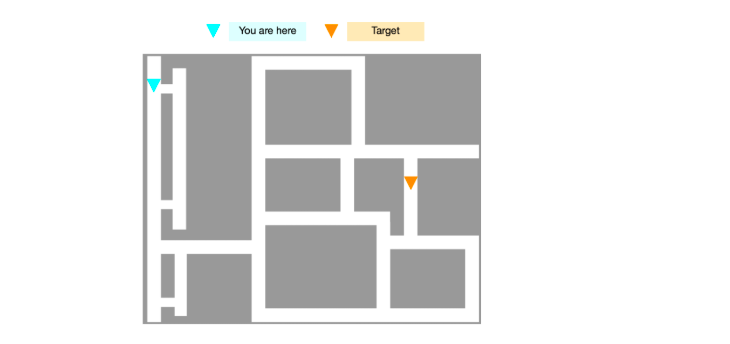
【导读】 从视觉观察中学习是强化学习(RL)中的一个基本但具有挑战性的问题。尽管算法与卷积神经网络相结合已被证明是成功的秘诀,但当...

来源:腾讯技术工程微信号 作者:黄华,腾讯 TEG 云架构平台部研发工程Elasticsearch 在腾讯内部广泛应用于日志实时分析、结构化数据分...

来源:腾讯技术工程微信号 作者:andyawang,腾讯 CSIG 后台开发工程师疫情期间,学校网课需求激增,腾讯课堂 2 天上线极速版,2 周内支...

原文最初发布在 SICARA 博客,经原作者 Etienne Bennequin 授权,InfoQ 中文站翻译并分享。

简单说一下断点调试的使用场景当业务代码很复杂,想要知道每一步的变量及对应的值。学习一个新框架,熟悉框架的执行流程不确定代码会运...

论文题目:Imagination-Augmented Agents for Deep Reinforcement Learning

论文题目:Learning Predictive Models From Observation and Interaction

论文题目:model-ensemble trust-region policy optimization












