论文题目:Model-Based Reinforcement Learning via Meta-Policy Optimization

论文题目:Recurrent World Models Facilitate Policy Evolution

model-free的强化学习算法已经在Atari游戏上取得了巨大成功,但是与人类选手相比,model-free的强化学习算法需要的交互数据...
足球机器人排成一排向球门发起射击,但守门员却并没有准备防守,而是一屁股倒在地上开始胡乱摆动起了双腿。然后,前锋跳了一段十分令人...
今天给大家介绍提升方法(Boosting), 提升算法是一种可以用来减小监督式学习中偏差的机器学习算法。

A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer: Fuli Luo, Peng Li, Jie Zhou, Pengcheng Yang, Baob...

如果人工智能是一块蛋糕,那么蛋糕的大部分是自监督学习,蛋糕上的糖衣是监督学习,蛋糕上的樱桃是强化学习。作者:Amit Chaudhary编译...
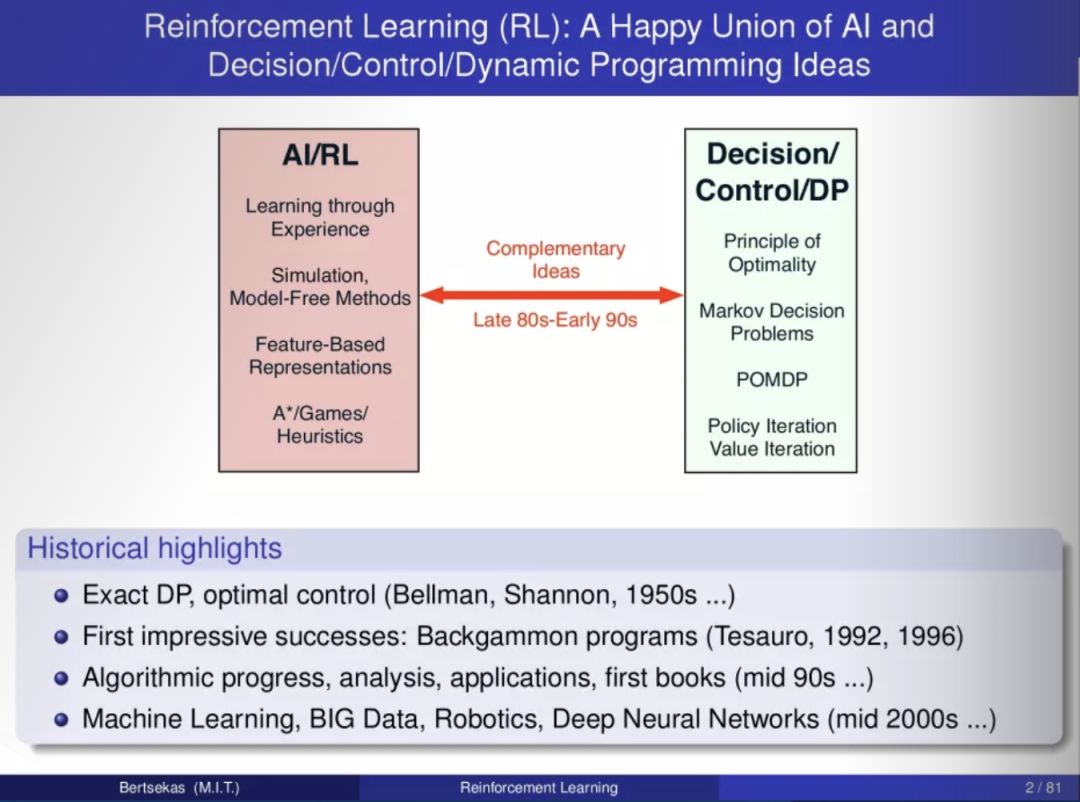
本文作者来自于宾夕法尼亚州立大学,总结了《十个关键点》,强化学习和最优控制的81页PPT汇总。来源:book.yunzhan365报道:深度强化学...
这篇文章是自己在上大数据分析课程时老师推荐的一篇文章,当时自己听着也是对原作者当年的的思路新奇非常敬佩,相信很多伙...
将其扩展到MCTS上,得到了 Maximum Entropy for Tree Search (MENTS)算法。
论文题目:SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards
论文题目:Reinforcement Learning with Deep Energy-Based Policies

【论文阅读】Mastering Complex Control in MOBA Games with Deep Reinforcement Learning

在开始说基于Stochastic Policy的方法之前,我们需要了解一下Policy Gradient的方法。在Policy Gradient里面有一个非常重要...

在强化学习中的值函数近似算法文章中有说怎么用参数方程去近似state value ,那policy能不能被parametrize呢?其实policy可...

在开始说值函数近似方法之前,我们先回顾一下强化学习算法。强化学习算法主要有两大类Model-based 的方法和Model-free 的方...

在上一篇文章强化学习中的无模型预测中,有说过这个无模型强化学习的预测问题,通过TD、n-step TD或者MC的方法能够获得值函...

在大多是强化学习(reinforcement learning RL)问题中,环境的model都是未知的,也就无法直接做动态规划。一种方法是去学MDP...

上一节我们说了马尔可夫决策过程,它是对完全可观测的环境进行描述的,也就是观测到的内容完整决定了决策所需要的特征。马...
马尔可夫决策过程 (Markov Decision Process,MDP)是序贯决策(sequential decision)的数学模型,一般用于具备马尔可夫性的...








