自从基于Stable Diffusion的生成模型大火以后,基于GAN的研究越来越少了,但是这并不能说明他就没有用了。异常检测是多个研究领域面临的...
GPTs prompts灵感库:创意无限,专业级创作指南,打造吸睛之作的秘诀优质prompt展示1.1 极简翻译中英文转换 {代码...} 1.2 完蛋,我被美...
在这篇文章中,我将介绍AutoGen的多个代理的运行。这些代理将能够相互对话,协作评估股票价格,并使用AmCharts生成图表。
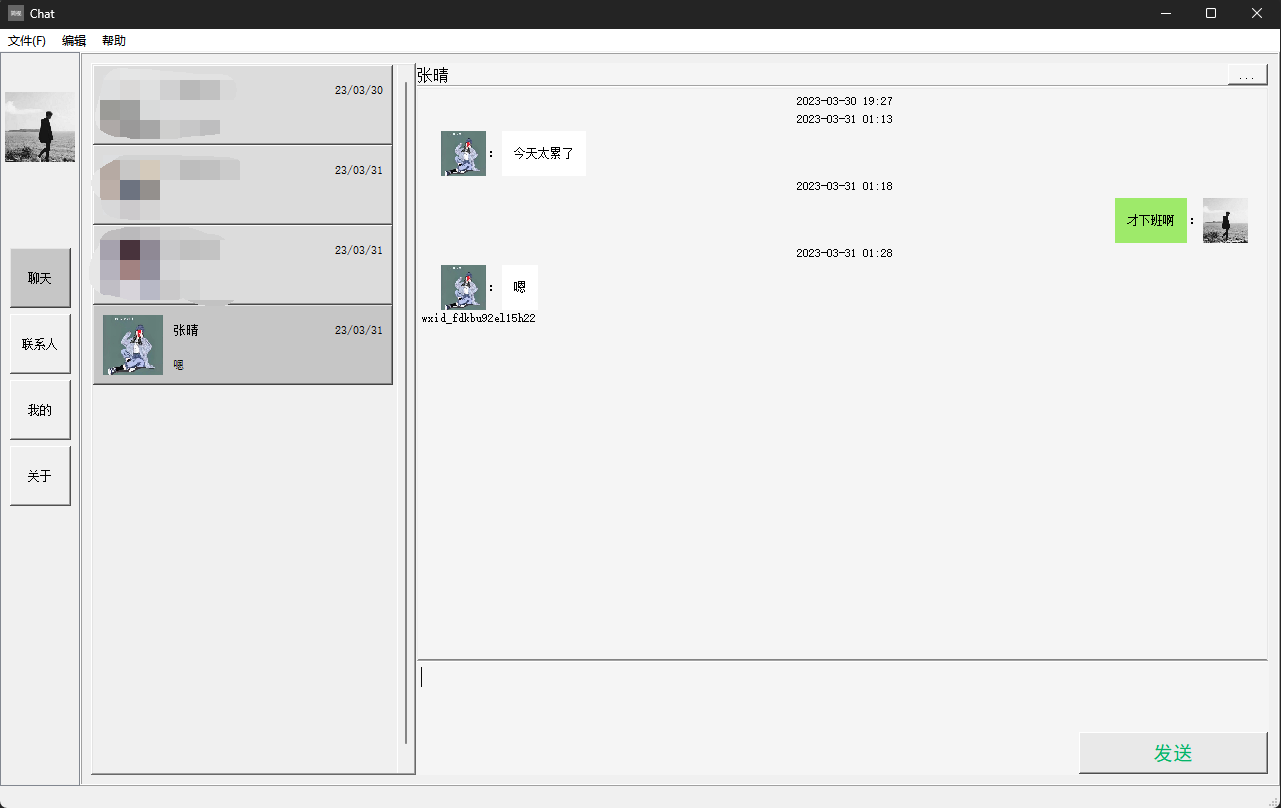
一个用于提取微信聊天记录的工具,支持将聊天记录导出成HTML、Word、CSV文档,以实现永久保存。此外,该工具还具有对聊天记录进行分析的...
为了增强CLIP在图像理解和编辑方面的能力,上海交通大学、复旦大学、香港中文大学、上海人工智能实验室、澳门大学以及MThreads Inc.等知...
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法,包括:Torch.compile: PyTorch模型的编译器GPU量化:通过降低精...
LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,旨在训练能够处理和生成自然语言文本的大型模型。
AI 工具 GNoME 发现 220 万种新晶体,相当于人类科学家 800 年的实验产出,其中 38 万种新晶体可以成为未来高新技术的稳定材料。

大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战...
今年大语言模型的快速发展导致像BERT这样的模型都可以称作“小”模型了。Kaggle LLM比赛LLM Science Exam 的第四名就只用了deberta,这可...
今年大语言模型的快速发展导致像BERT这样的模型都可以称作“小”模型了。Kaggle LLM比赛LLM Science Exam 的第四名就只用了deberta,这可...
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质...
大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。

老潘用triton有两年多了,一直想写个教程给大家。顺便自己学习学习,拖了又拖,趁着这次换版本的机会,终于有机会了写了。

量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相...
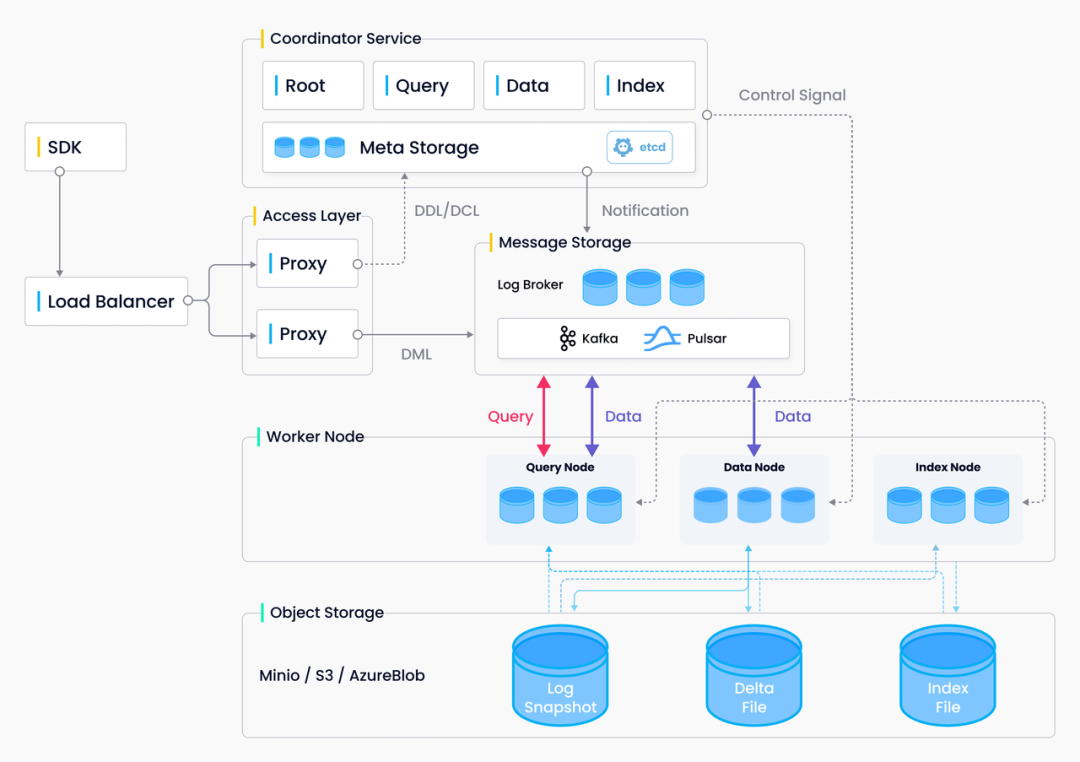
随着大模型的爆火,向量数据库也越发成为开发者关注的焦点。为了方便大家更好地了解向量数据库,我们特地推出了《Hello, VectorDB》系列...
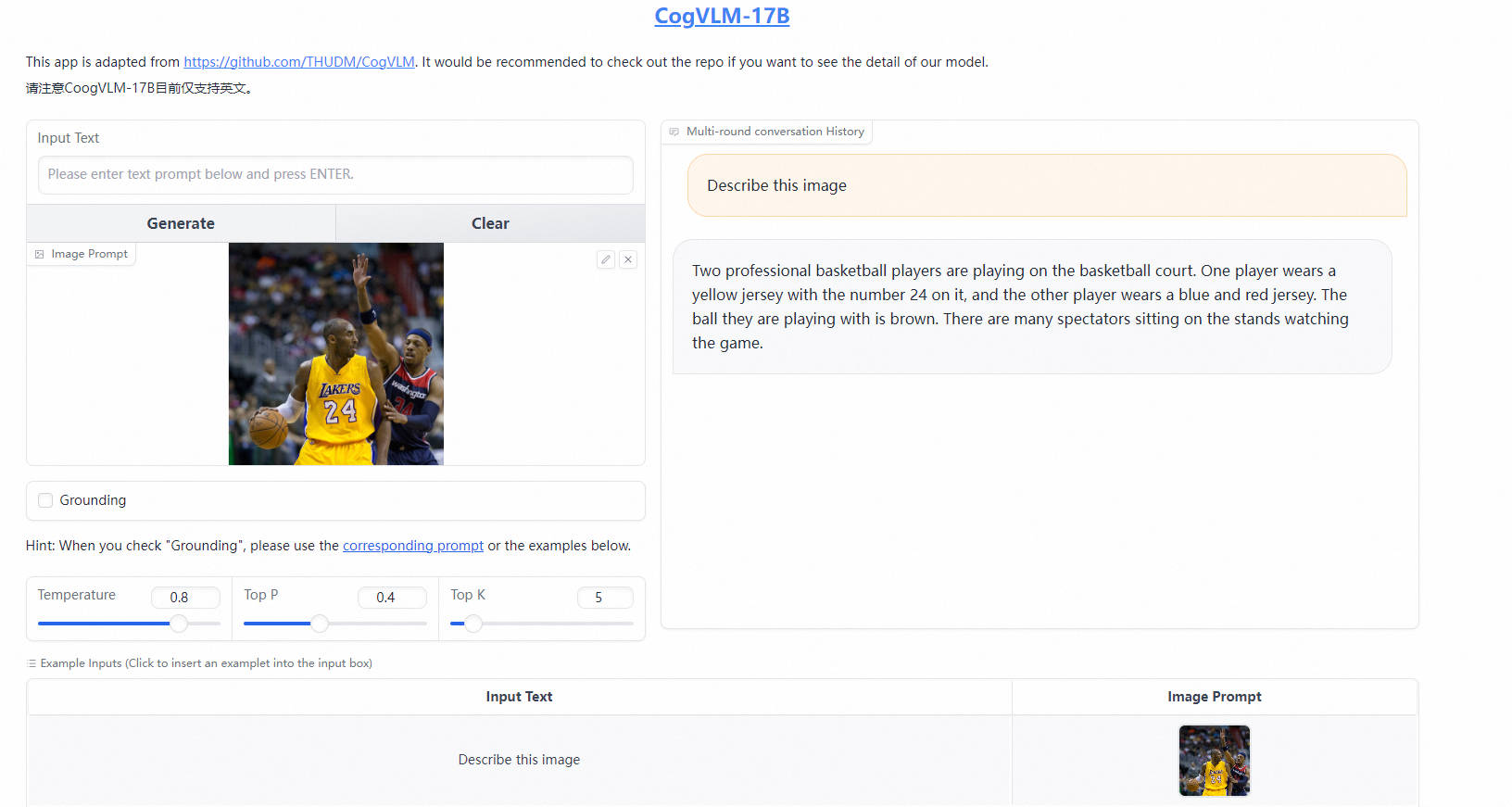
CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数。
现代的人工智能硬件架构(例如,Nvidia Hopper, Nvidia Ada Lovelace和Habana Gaudi2)中,FP8张量内核能够显著提高每秒浮点运算(FLOPS),...
大环类化合物是指由 12 个以上原子组成的小分子或肽。相较于其他小分子化合物,大环类化合物在结构和性能上有着诸多优势,也因此被视为...

近半年来如火如荼的「百模大战」让越来越多的终端厂商卷进来,机器人、音箱、手表、眼镜等硬智能硬件产品加持大模型能力,让产品快速接...









