上面的图像,类型(A)显示了检索到的数据或文档回答查询的位置。LLM仅使用NLG从提供的数据中格式化答案。
2022 年 11 月,ChatGPT 发布掀起 AI 狂潮。时隔 1 年,2023 年 11 月,ChatGPT 之父、Sam Altman 的一项人事巨变,再次掀起了一场 AI ...

在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩...
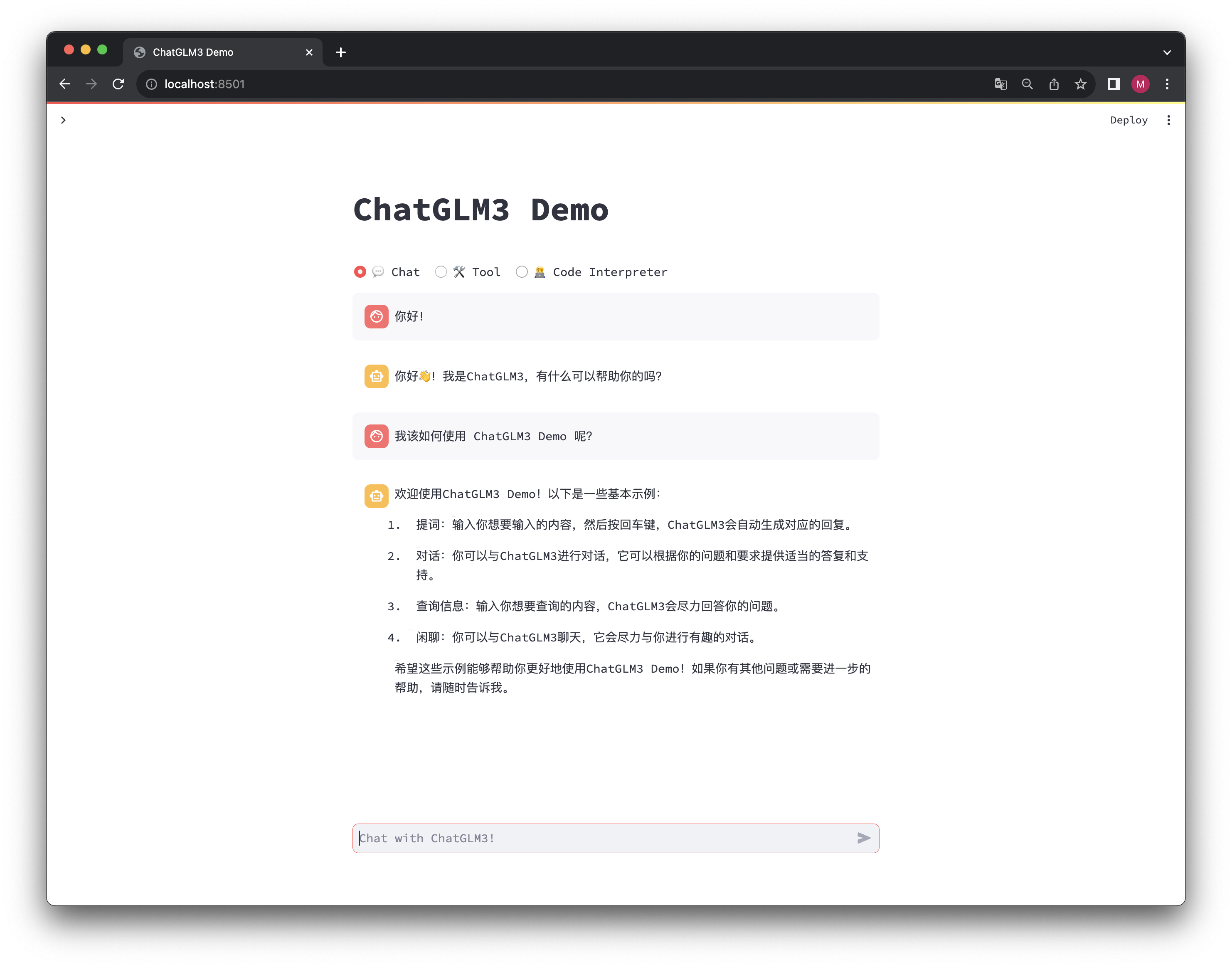
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代...
具有专家混合(MoEs)的稀疏激活mlp在保持计算常数的同时显着提高了模型容量和表达能力。此外gMLP表明,所有mlp都可以在语言建模方面与tra...
铭文、碑刻是过去文明的思想、文化和语言的体现。金石学家破译千年前的密码,需要完成文本修复、时间归因和地域归因三大任务。

AutoGen作为一个最大化LLM(如GPT-4)能力的框架而脱颖而出。由微软研究院开发的AutoGen通过提供一种自动化、优化和编排工作流的方法,简...
Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差...
CodeShell是北京大学知识计算实验室联合四川天府银行AI团队研发的多语言代码大模型基座。它拥有70亿参数,经过对五千亿Tokens的训练,并...

由于现有基准和指标的限制,在开放式环境中评估大型语言模型(llm)是一项具有挑战性的任务。为了克服这一挑战,本文引入了微调llm作为可...
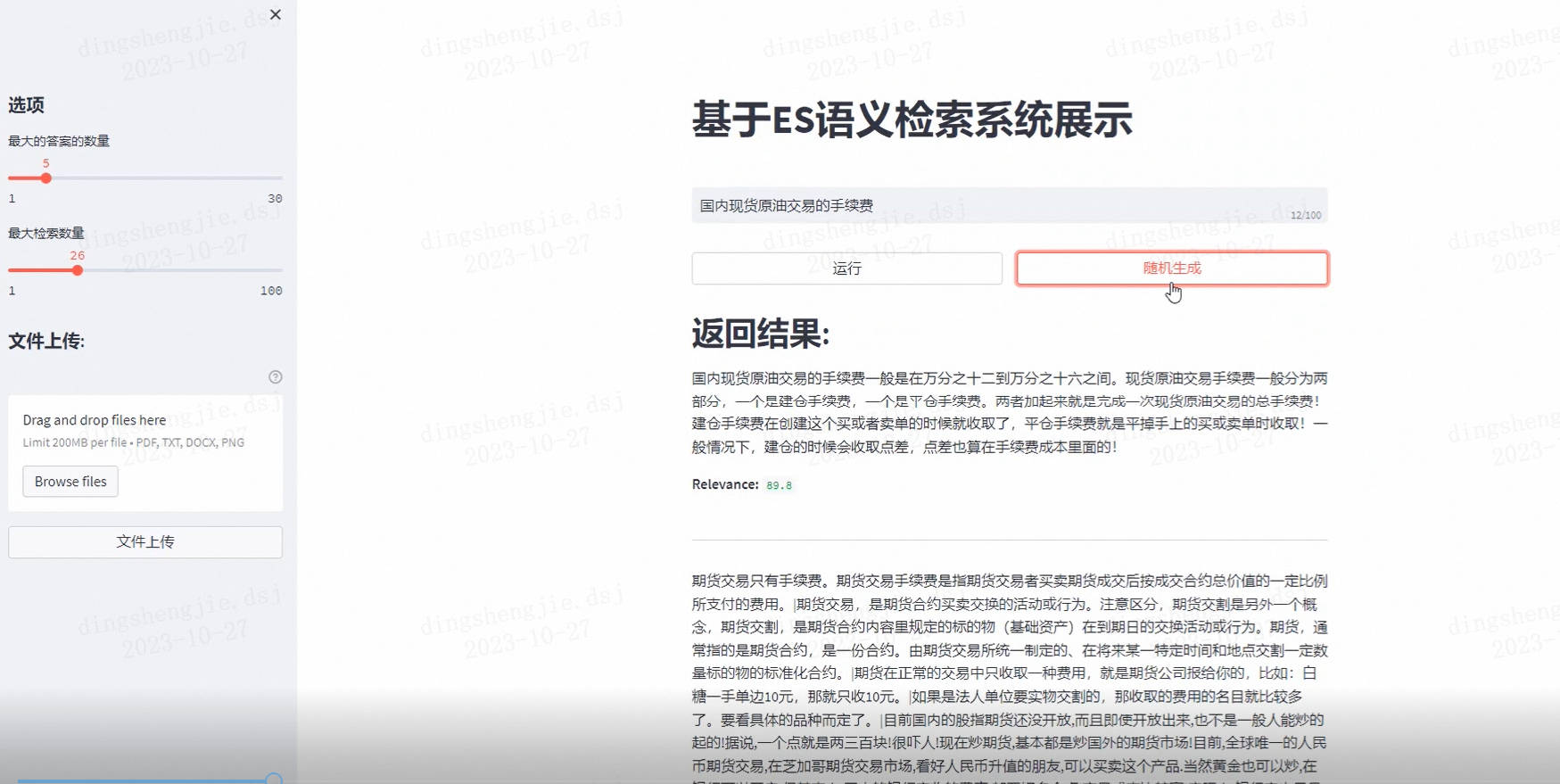
elasticsearch 提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词...

生物信息学 (Bioinformatics) 是指利用应用数学、信息学、统计学和计算机科学的方法,研究生物学问题。随着计算机科学技术的发展,AI 在...

Autogen是一个卓越的人工智能系统,它可以创建多个人工智能代理,这些代理能够协作完成任务,包括自动生成代码,并有效地执行任务。
一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务...
检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用...
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动...
PaddleNLP Pipelines 是一个端到端智能文本产线框架,面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力。本项目将通过一种简单...
随着物流订单达到新的量级,传统物流运输过程无法实时监控与管理,同时人力作业也难以保证其效率,容易出现各种意外风险,因此仓储物流...

2022年的LoRA提高了微调效率,它在模型的顶部添加低秩(即小)张量进行微调。模型的参数被冻结。只有添加的张量的参数是可训练的。
LLM的火爆之后,英伟达(NVIDIA)也发布了其相关的推理加速引擎TensorRT-LLM。TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含...







