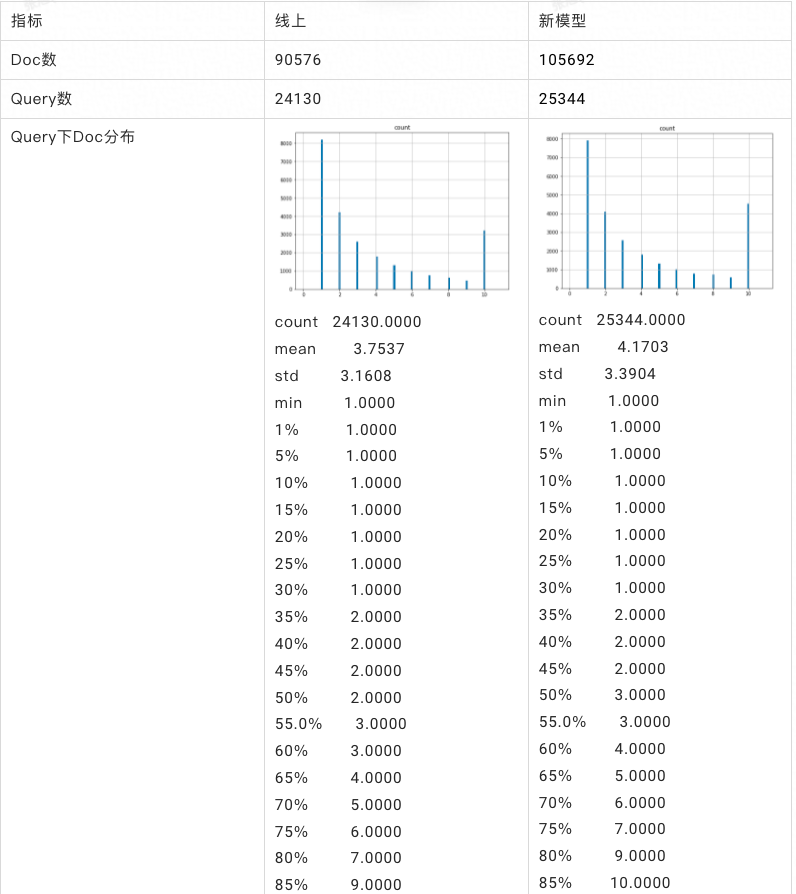
ChatGPT 爆火后,大语言模型一跃而至,成为了行业与资本的宠儿。而在人们或是猎奇、或是探究地一次次对话中,大语言模型所表现出的过度...

GPTs prompts灵感库:创意无限,专业级创作指南,打造吸睛之作的秘诀优质prompt展示1.1 极简翻译中英文转换 {代码...} 1.2 完蛋,我被美...
一个用于提取微信聊天记录的工具,支持将聊天记录导出成HTML、Word、CSV文档,以实现永久保存。此外,该工具还具有对聊天记录进行分析的...
LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,旨在训练能够处理和生成自然语言文本的大型模型。
探索多模态语言模型整合了多种数据类型,如图像、文本、语言、音频等异质性。尽管最新的大型语言模型在基于文本的任务上表现出色,但它...

大型语言模型(LLMs)具有出色的能力,但由于完全依赖其内部的参数化知识,它们经常产生包含事实错误的回答,尤其在长尾知识中。

随着大模型的爆火,向量数据库也越发成为开发者关注的焦点。为了方便大家更好地了解向量数据库,我们特地推出了《Hello, VectorDB》系列...
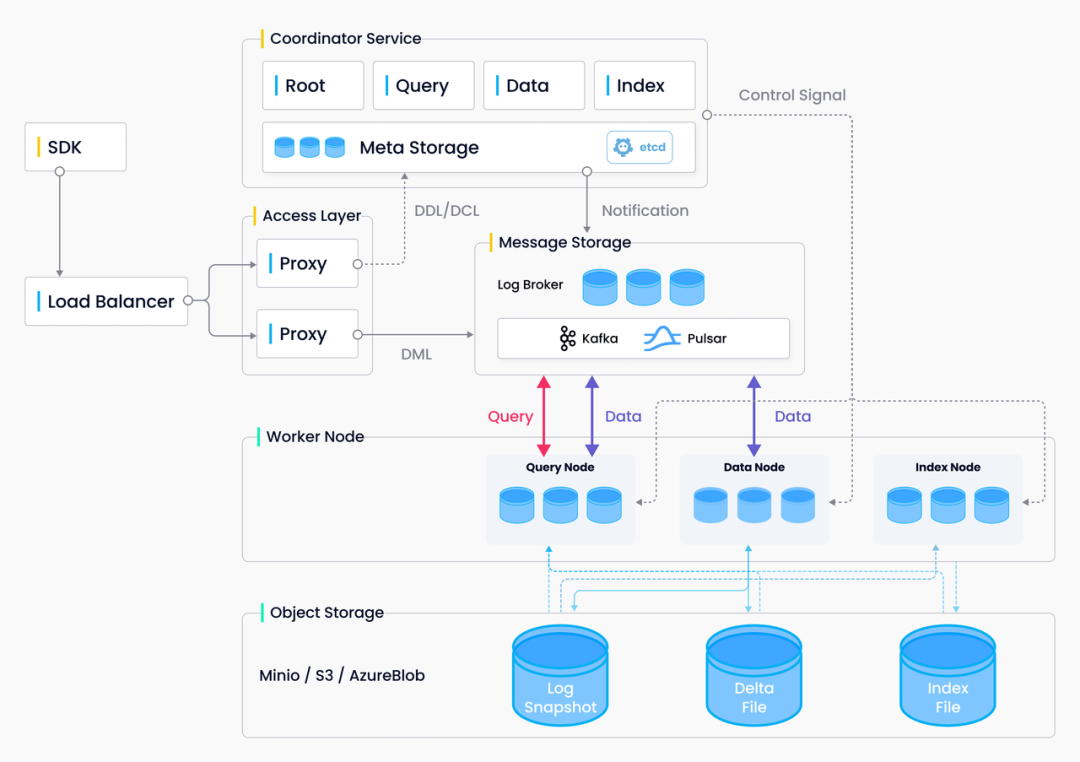
Receptance Weighted Key Value(RWKV)是pengbo提出的一个新的语言模型架构,它使用了线性的注意力机制,把Transformer的高效并行训练...

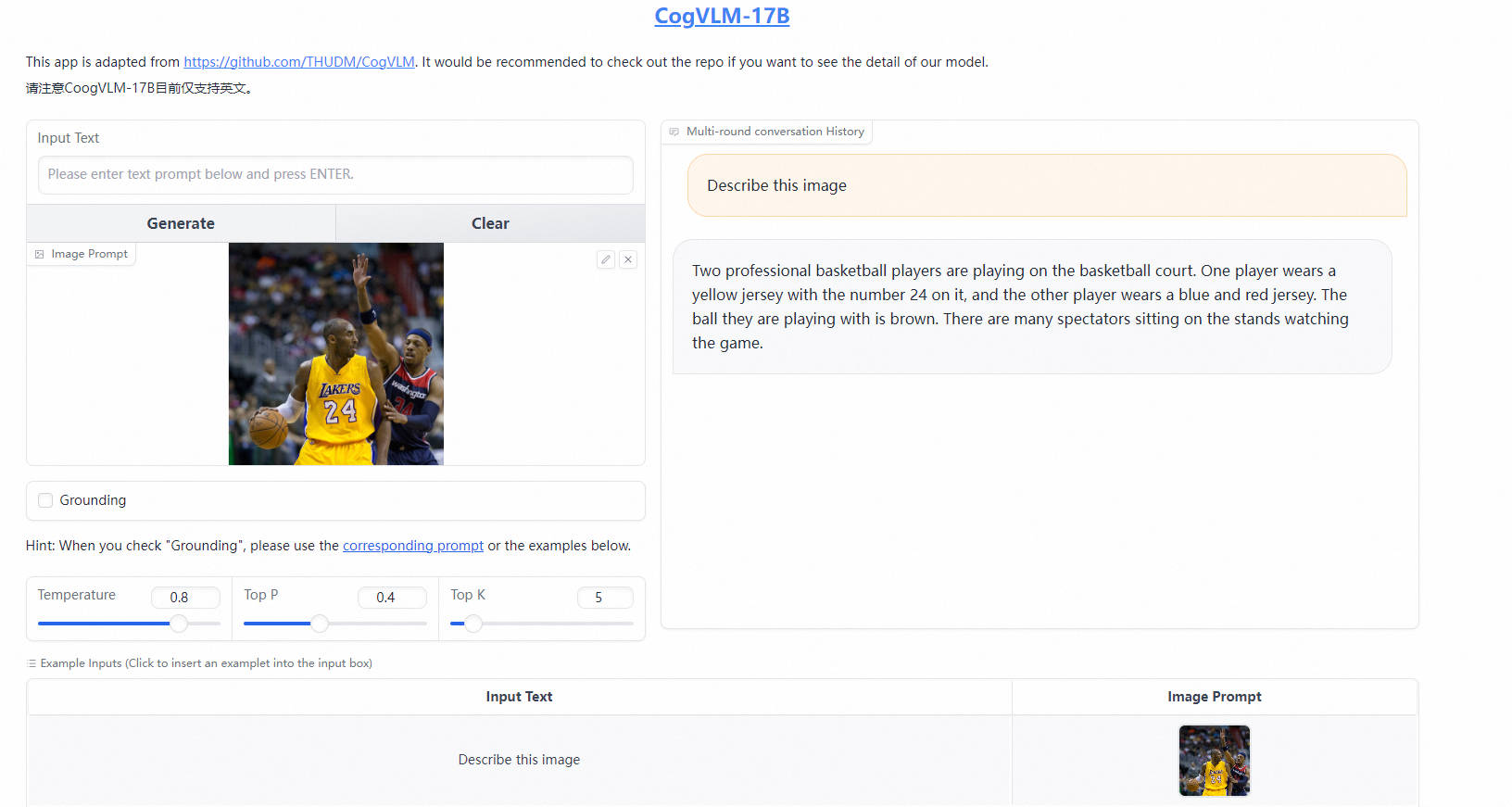
CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数。
2022 年 11 月,ChatGPT 发布掀起 AI 狂潮。时隔 1 年,2023 年 11 月,ChatGPT 之父、Sam Altman 的一项人事巨变,再次掀起了一场 AI ...

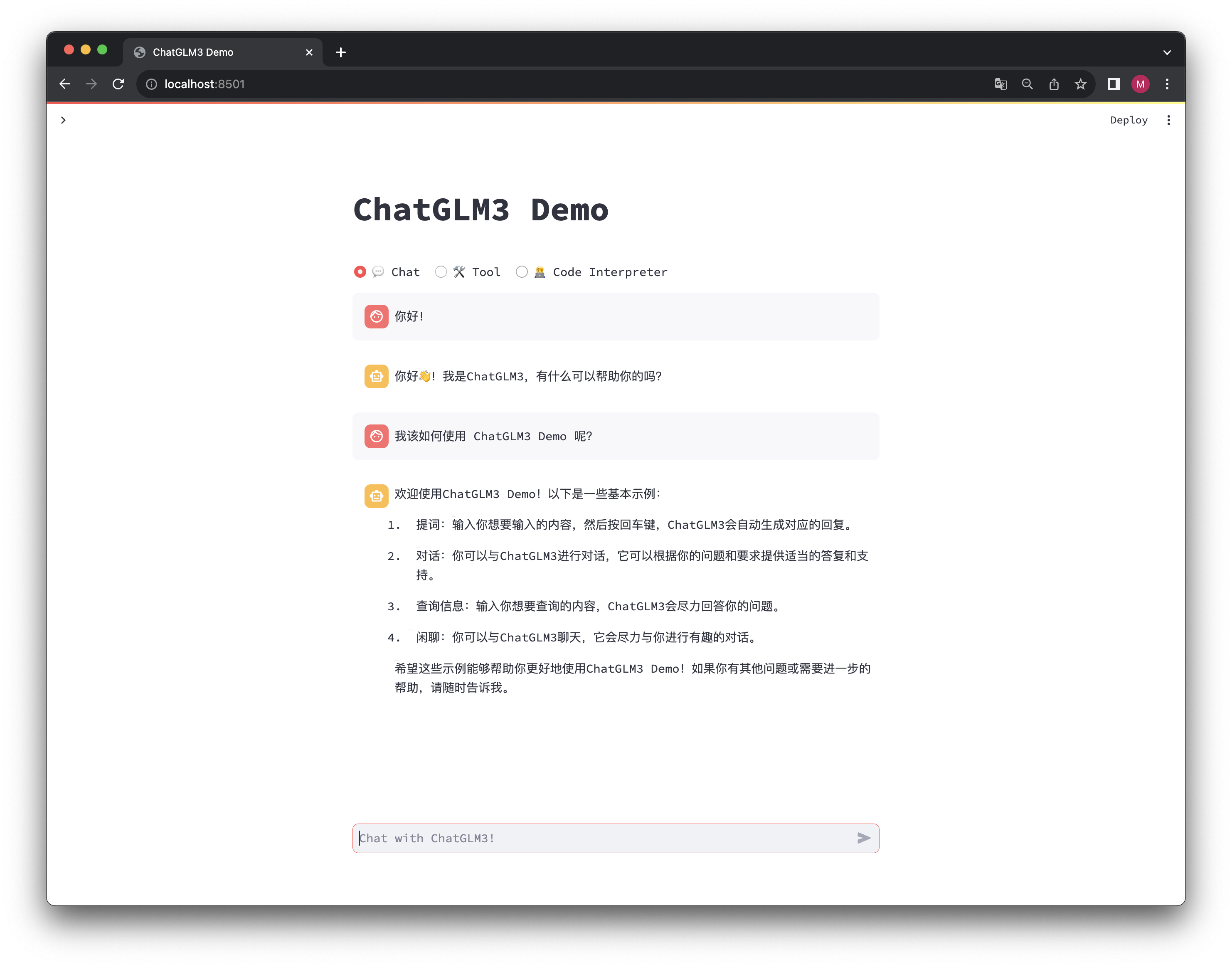
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代...
CodeShell是北京大学知识计算实验室联合四川天府银行AI团队研发的多语言代码大模型基座。它拥有70亿参数,经过对五千亿Tokens的训练,并...

elasticsearch 提供了几个内置的分词器:standard analyzer(标准分词器)、simple analyzer(简单分词器)、whitespace analyzer(空格分词...

一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务...
PaddleNLP Pipelines 是一个端到端智能文本产线框架,面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力。本项目将通过一种简单...
因为 ElasticSearch 是用 Java 语言编写的,所以必须安装 JDK 的环境,并且是 JDK 1.8 以上,具体操作步骤自行百度
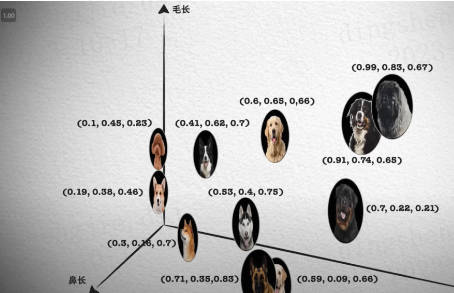
通过将复杂的对象(例如文本、图像或声音)转换为数值向量,并在多维空间中进行相似性搜索,它能够实现高效的查询匹配和推荐。
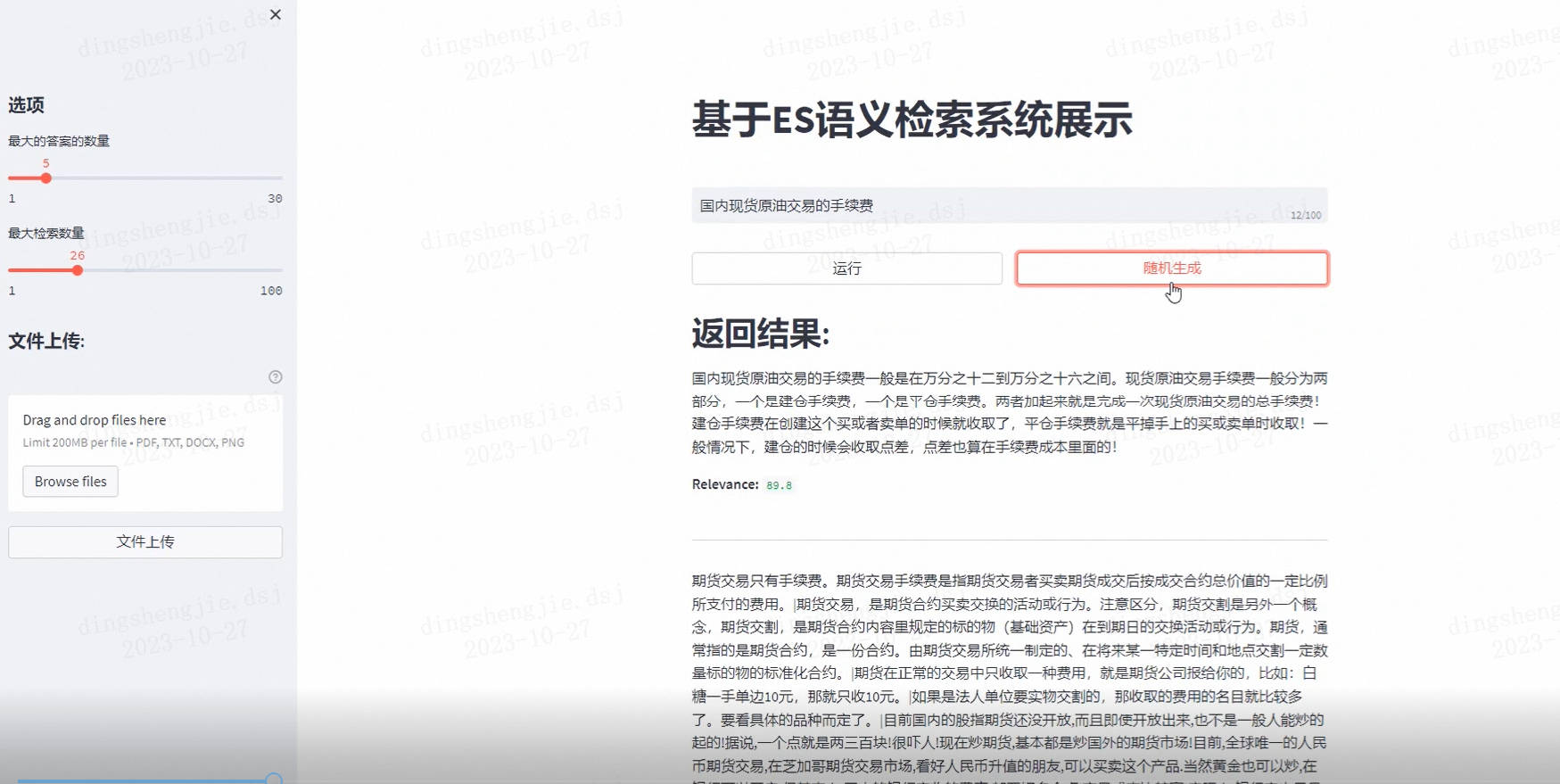
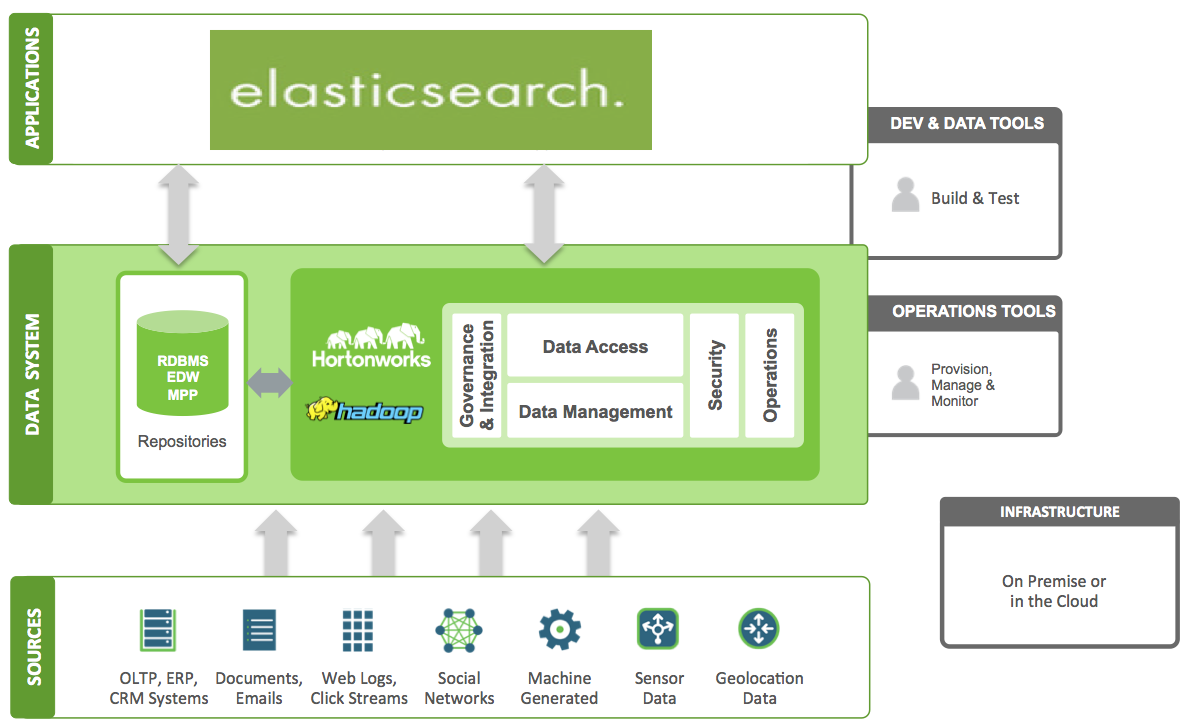
今天要介绍的 Elasticsearch Relevance Engine™ (ESRE™),提供了多项用于创建高度相关的 AI 搜索应用程序的新功能。ESRE 站在 Elastic ...
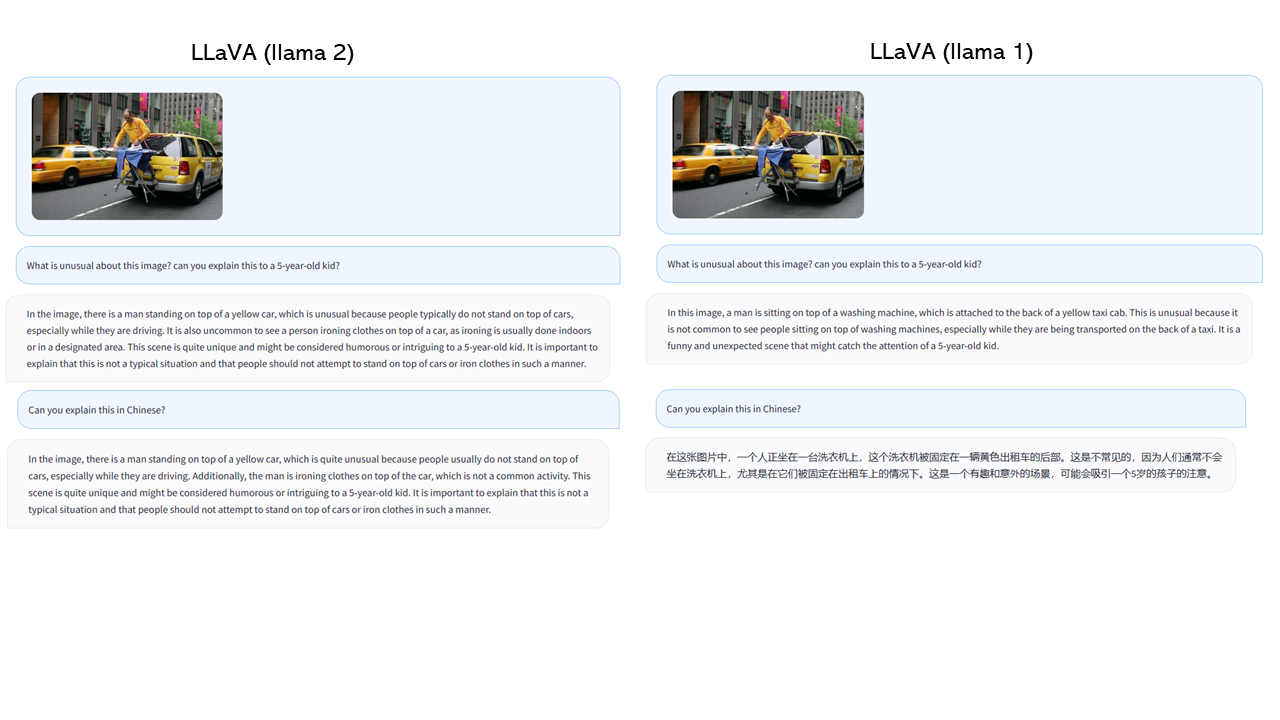
一个面向多模式GPT-4级别能力构建的助手。它结合了自然语言处理和计算机视觉,为用户提供了强大的多模式交互和理解。LLaVA旨在更深入地...
近年来,基于向量进行召回的做法在搜索和推荐领域都得到了比较广泛的应用,并且在学术界发表的论文中,基于向量的 dense retrieve 的方...