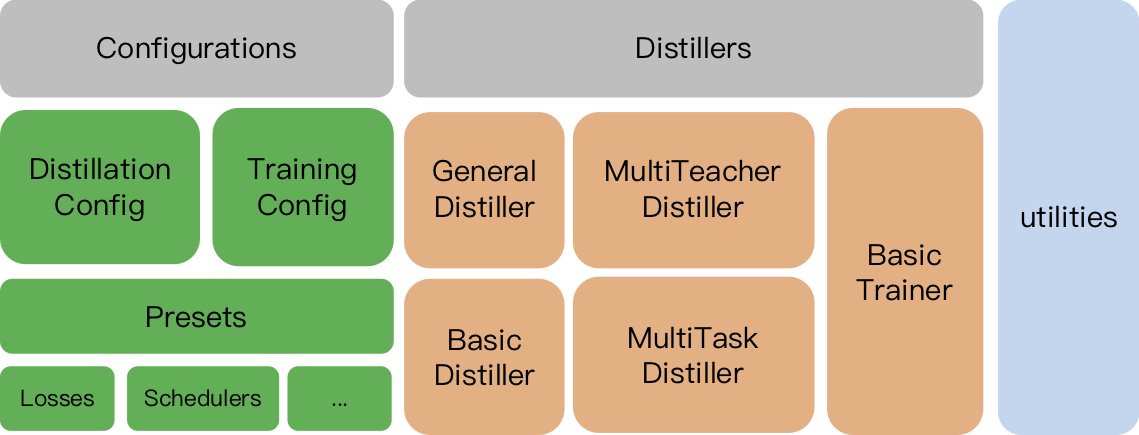
TextBrewer是一个基于PyTorch的、为实现NLP中的知识蒸馏任务而设计的工具包,融合并改进了NLP和CV中的多种知识蒸馏技术,提供便捷快速的...
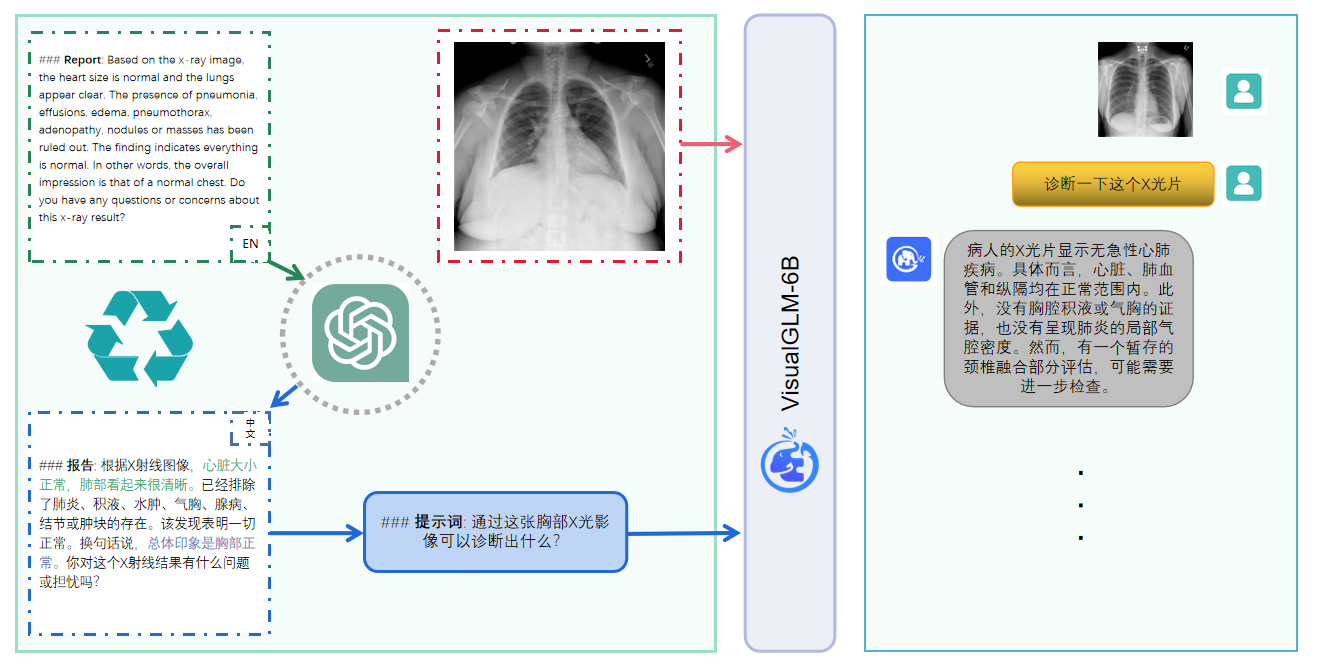
多模态预训练模型通过在多种模态的大规模数据上的预训练,可以综合利用来自不同模态的信息,执行各种跨模态任务。在本项目中,我们推出...

ChatGPT/GLM提供图形交互界面,特别优化论文阅读/润色/写作体验,模块化设计,支持自定义快捷按钮&函数插件,支持Python和C++等项目剖析...
语义索引(可通俗理解为向量索引)技术是搜索引擎、推荐系统、广告系统在召回阶段的核心技术之一。语义索引模型的目标是:给定输入文本...
最近,通用领域的大语言模型 (LLM),例如 ChatGPT,在遵循指令和产生类似人类响应方面取得了显著的成功,这种成功间接促进了多模态大模...
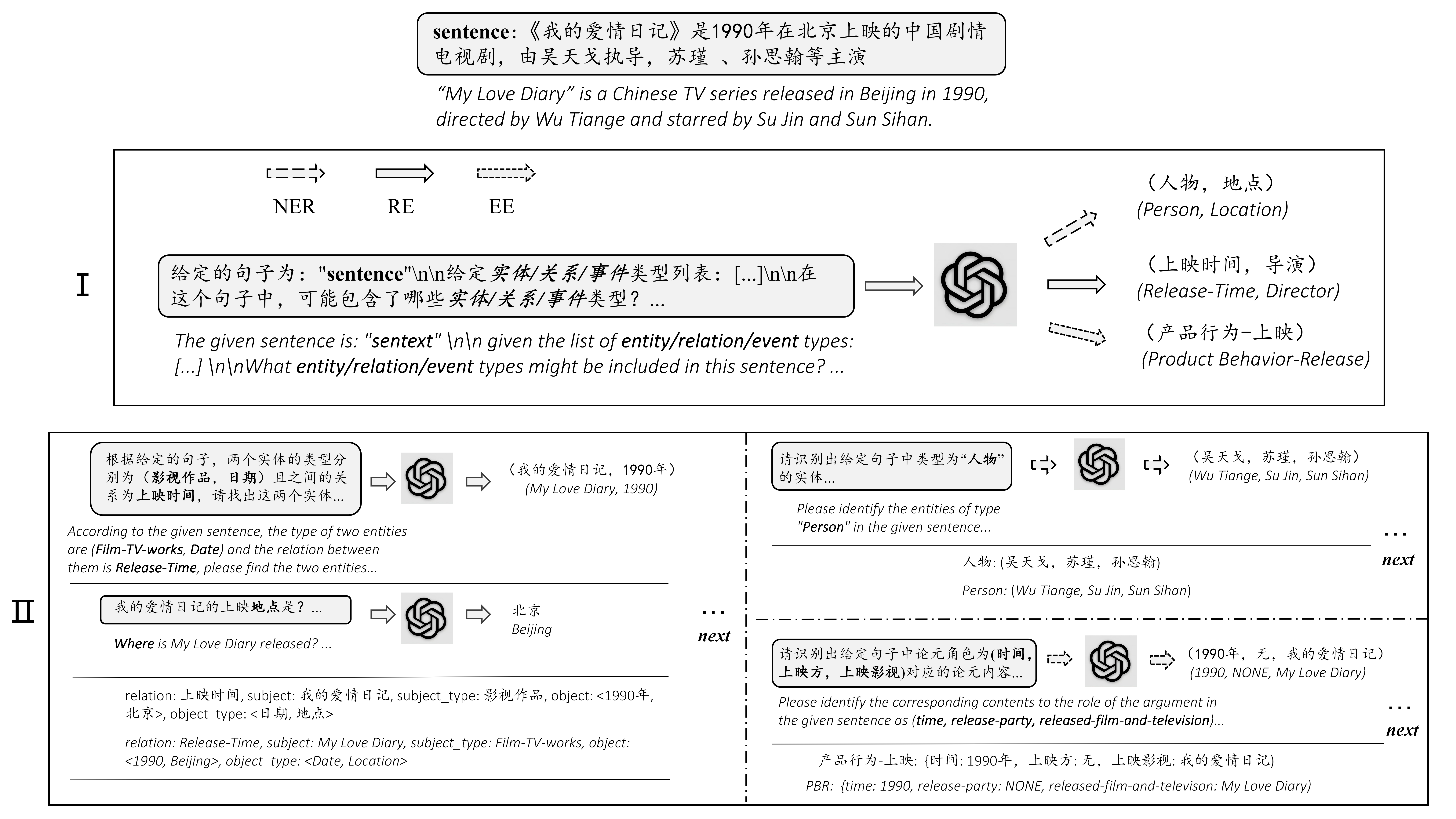
零样本信息抽取(Information Extraction,IE)旨在从无标注文本中建立IE系统,因为很少涉及人为干预,该问题非常具有挑战性。但零样本I...
从零构建医疗领域知识图谱的KBQA问答系统:其中7类实体,约3.7万实体,21万实体关系。项目效果以下两张图是系统实际运行效果:1.项目运...

这是微软发布在2022 ICML的论文,MoE可以降低训练成本,但是快速的MoE模型推理仍然是一个未解决的问题。所以论文提出了一个端到端的MoE...
Title: SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs Paper: [链接]Code: [链接]

记得在2022年年底,生成式AI与大模型开始爆火的时候,我们就曾讨论过一个问题:这轮AI浪潮中,最先受到深刻影响的将是云计算市场。

大型语言模型(llm)是一种人工智能(AI),在大量文本和代码数据集上进行训练。它们可以用于各种任务,包括生成文本、翻译语言和编写不同类...
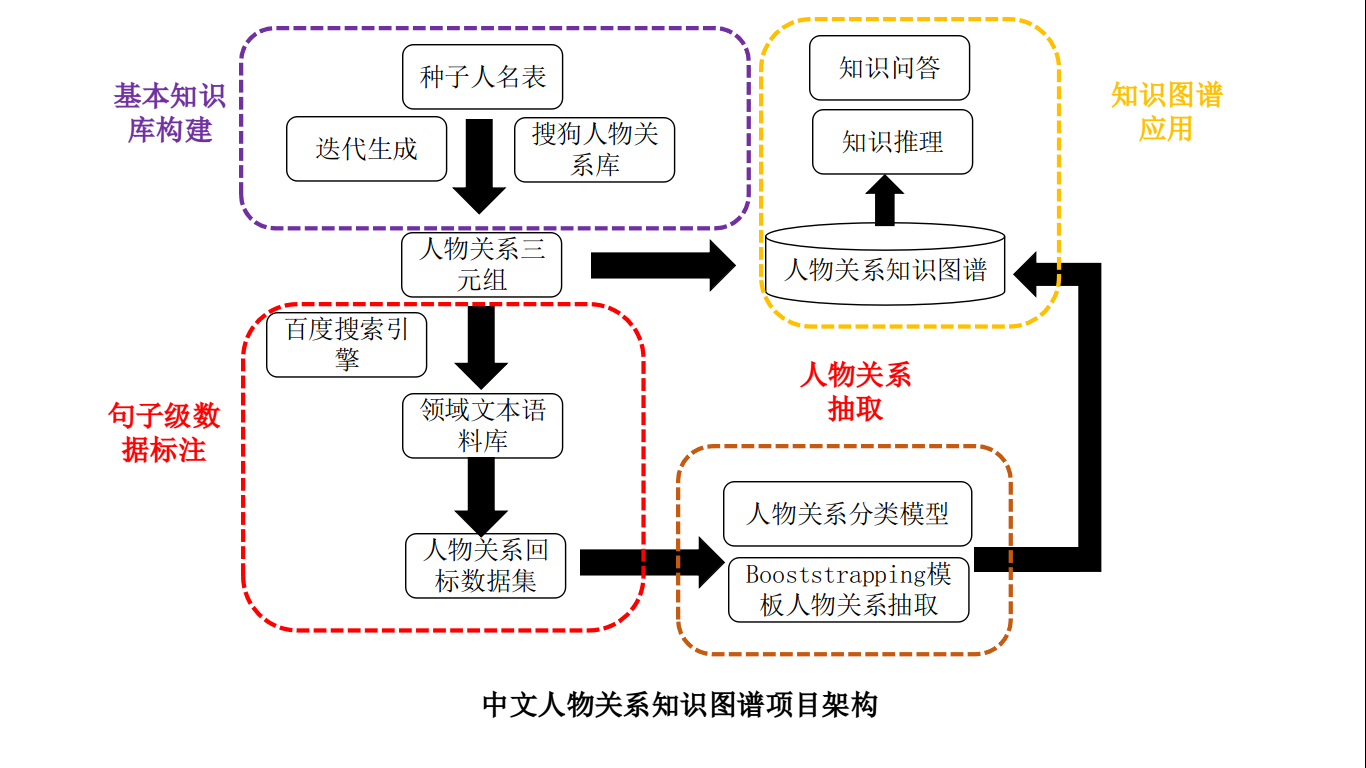
项目介绍知识抽取(实体关系抽取)是知识图谱构建中的核心环节,实体关系抽取作为一项基本技术在自然语言处理应用中扮演着重要作用.究其技...
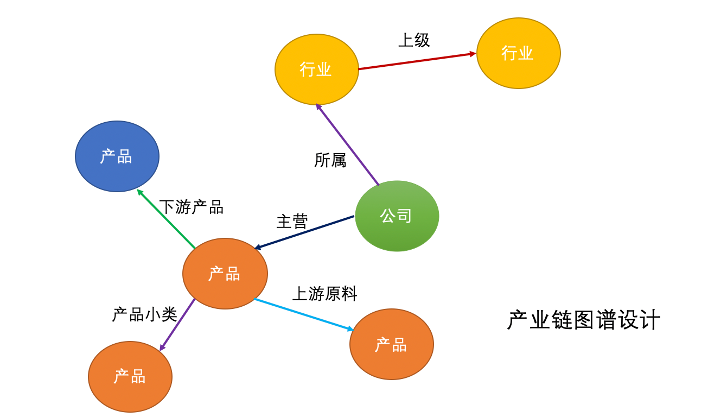
包括上市公司所属行业关系、行业上级关系、产品上游原材料关系、产品下游产品关系、公司主营产品、产品小类共6大类。 上市公司4,654家,...
文心千帆:PPT 制作、数字人主播一键开播等数十种应用场景惊艳到我了,下面给出简介和使用指南,快去使用起来吧

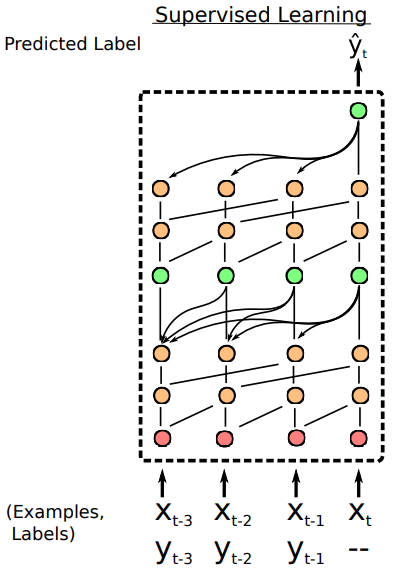
元学习可以被定义为一种序列到序列的问题,在现存的方法中,元学习器的瓶颈是如何去吸收同化利用过去的经验。注意力机制可以允许在历史...
Model-Agnostic Meta-Learning (MAML): 与模型无关的元学习,可兼容于任何一种采用梯度下降算法的模型。MAML 通过少量的数据寻找一个合...
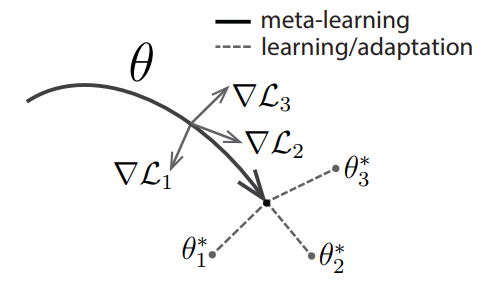
元学习 (Meta-Learning) 通常被理解为“学会学习 (Learning-to-Learn)”,指的是在多个学习阶段改进学习算法的过程。在基础学习过程中,内...
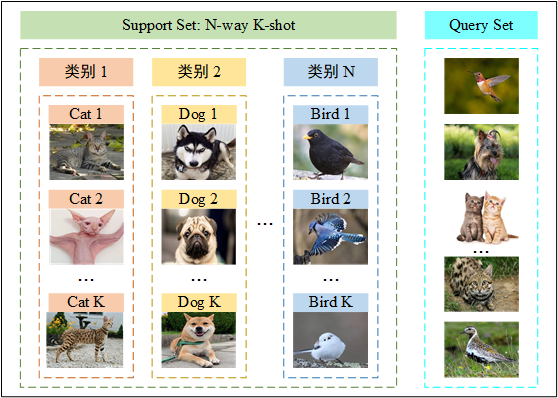
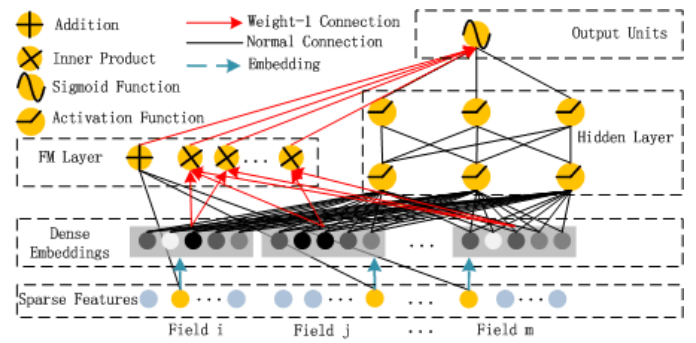
CTR预估是目前推荐系统的核心技术,其目标是预估用户点击推荐内容的概率。DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order(低阶...
在网络技术不断发展和电子商务规模不断扩大的背景下,商品数量和种类快速增长,用户需要花费大量时间才能找到自己想买的商品,这就是信...
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序...