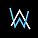今天要介绍的MobileAI2021的图像超分竞赛的最佳方案,无论是PSNR指标还是推理速度均显著优于其他方案,推理速度达到了手机端实时(<40...

NTIRE的各大竞赛已经落下帷幕,冠亚军排名也相继确定,笔者近期会逐步将相关领域的竞赛结果进行一下简单总结,同时也将对这其中的冠军军...

NTIRE的各大竞赛已经落下帷幕,冠亚军排名也相继确定,笔者近期会逐步将相关领域的竞赛结果进行一下简单总结,同时也将对这其中的冠军军...

一直以来,甚少有normalization技术在low-level得到广泛应用并取得优异性能,就算得到应用其性能也会受限或者造成异常的视觉效果。

本文是中科大团队用于参加NTIRE2021图像去模糊竞赛的方案EDPN,取得了Track1三指标第一,Track2赛道双指标第一的成绩。EDPN是在EDVR的基...

【GiantPandaCV导语】本文主要对2021年IEEE TRANSACTIONS ON IMAGE PROCESSING中由德克萨斯A&M大学和华中科技大学联合发表的EnlightenGA...
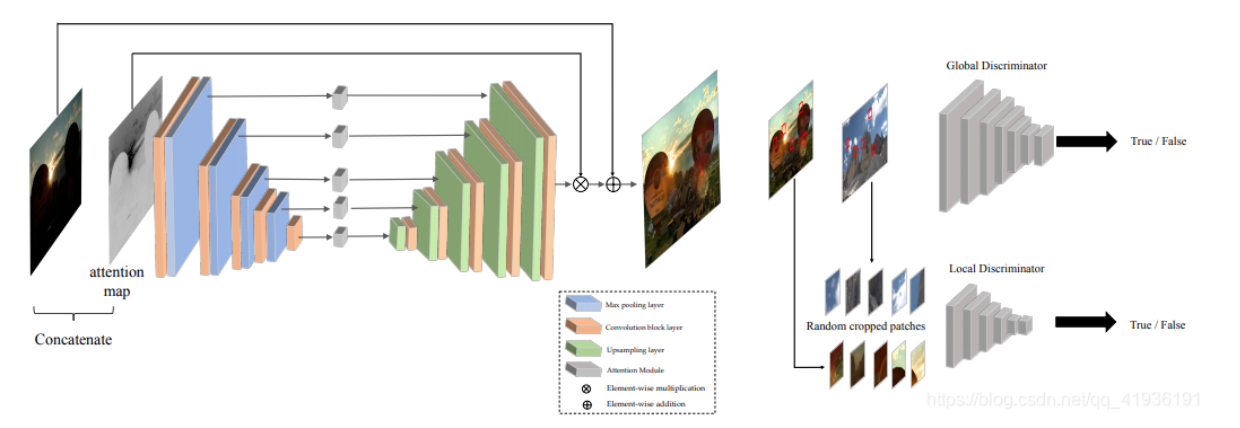
作者提出了一种能够推断出人类和物体的形状和空间排列的方法,只需要一张在自然环境中捕捉的图像,且不需要任何带有3D监督的数据集。该...
【GiantPandaCV导语】这篇文章主要从两个方面讨论了弱监督方法在森林病虫害检测中实际应用效果:弱监督的实质是什么,它与传统监督方式...

吸取CNN优点!LeViT:快速推理的视觉Transformer,在速度/准确性的权衡方面LeViT明显优于现有的CNN和视觉Transformer,比如ViT、DeiT等,...

Monocular Real-time Full Body Capture with Inter-part Correlations

经过几个月不停地跳票,我们的人脸检测+关键点检测算法(libfacedetection@GitHub)第三版终于发布了!我们原计划春节假期发布,结果难...

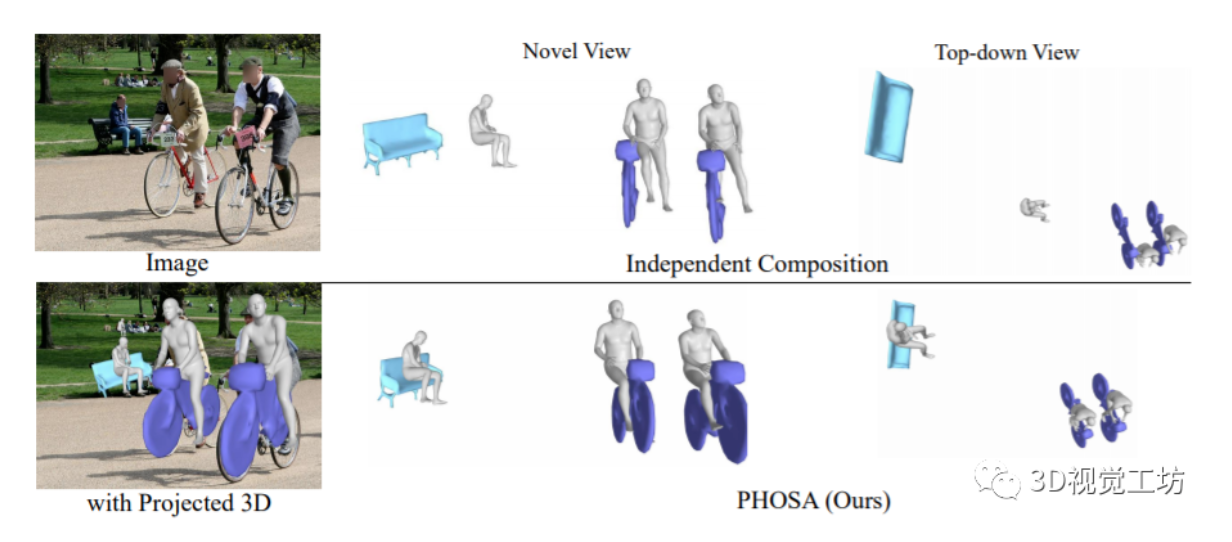
【GiantPandaCV导语】本文对anchor-free类检测方案中的基于特征采样点的实现思路实现的RepPoint网络进行了解读。
首发:AIWalker作者:HappyAIWalker标题&作者团队paper: [链接]code: [链接]本文是清华大学&旷视科技在结构重参数领域继ACNet、RepVGG、...

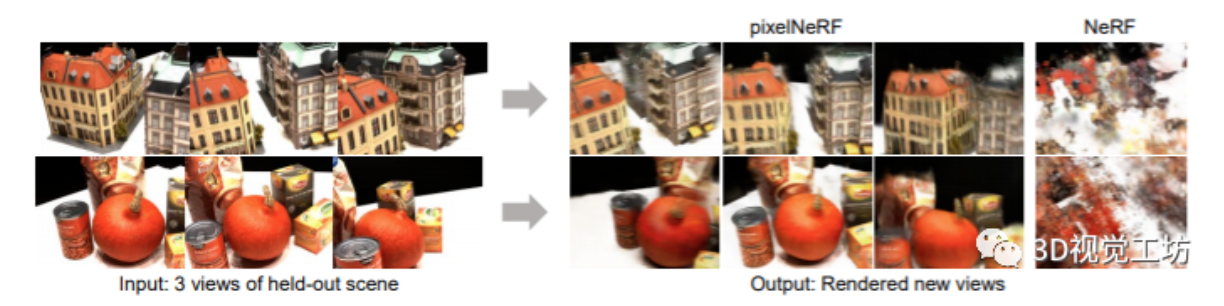
作者提出了pixelNeRF,一个只需要输入单张或多张图像,就能得到连续场景表示的学习框架。由于现存的构建神经辐射场【1】的方法涉及到独...
首发:AIWalker作者:HappyAIWalker标题&作者团队paper: [链接]code:[链接]\_transformer (暂未开源)本文是谷歌大脑的研究员(原ViT团队)...

首发:AIWalker作者:HappyAIWalker标题&作者团队paper: [链接]code: [链接]本文是南洋理工大学Chen Change Loy团队在视频超分方面最新...

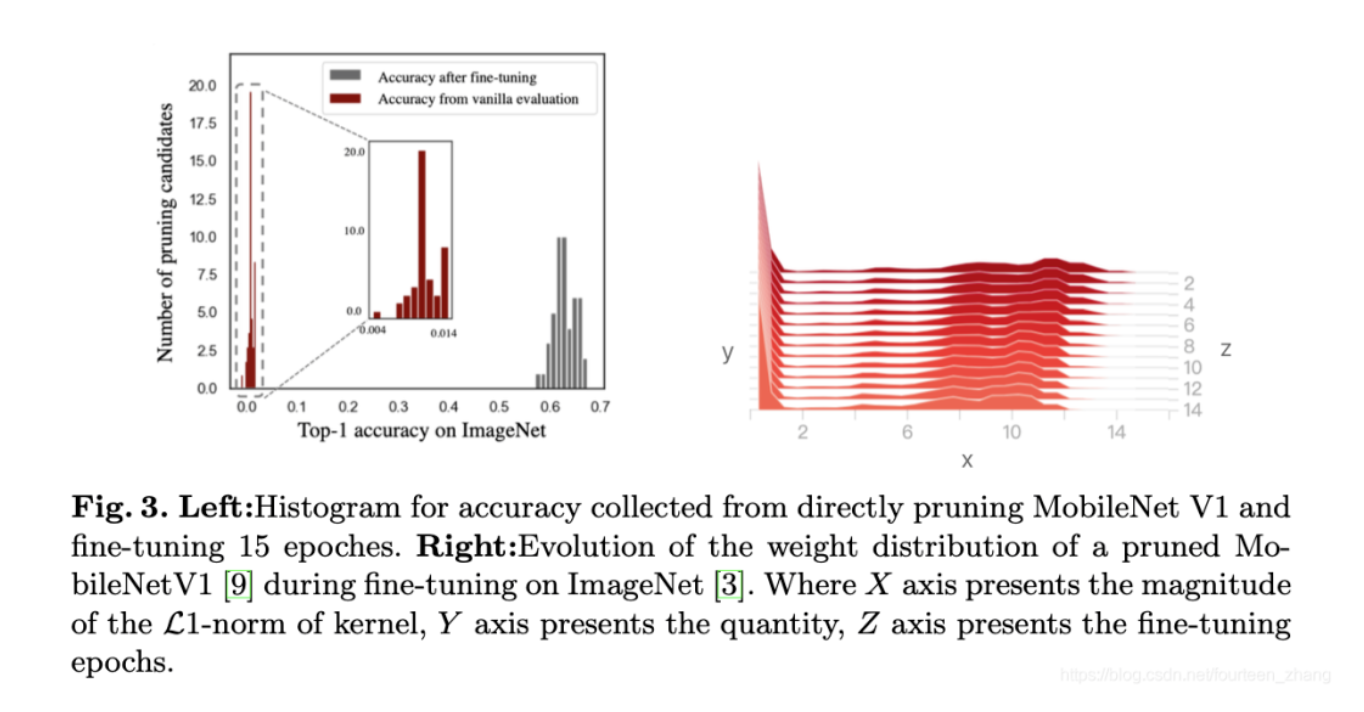
[GiantPandaCV导语]:模型剪枝算法核心在于找到“不重要”的参数并且实现裁剪。为寻找到较优的剪枝策略,我们往往需要尝试多种剪枝策略和...
首发:旷视研究院作者:R知乎:[链接]论文地址:[链接]论文代码:[链接]本文提出一种新的激活函数 ACON (activate or not),可以自适应...

我们知道,Tile 早在 2013 年就推出了第一款蓝牙追踪器,挂在行李、钥匙或包包上,可以帮忙用户寻找这些物品的位置。经过了八年发展,Ti...

首发:AI公园公众号 作者:Gidi Shperber编译:ronghuaiyang导读OCR中的研究,工具和挑战,都在这儿了。介绍我喜欢OCR(光学字符识别)。...