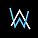由于在AI生成视频的时长上成功突破到一分钟,再加上演示视频的高度逼真和高质量,Sora立刻引起了轰动。在Sora横空出世之前,Runway一直...

NVIDIA Metropolis 微服务提供功能强大且可自定义的云原生 API 和微服务,用于开发视觉 AI 应用和解决方案。该框架现在涵盖 NVIDIA Jets...

边缘视觉 AI 应用的开发周期往往漫长且昂贵。同时,快速开发灵活、安全的云原生边缘 AI 应用的重要性也变得前所未有。现在,全新 NVIDIA...
在Transformer如日中天时,一个称之为“Mamba”的架构横冲出世,在语言建模上与Transformers不相上下,具有线性复杂度,同时具有5倍的推理...

Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集...

近年来,视觉Transformer及其各种形式在人体姿态估计中具有重要意义。通过将图像块视为Token,Transformer可以明智地捕获全局关系,通过...

数据集包含 360 张红血细胞图像及其注释文件,分为训练集与验证集。训练文件夹包含 300 张带有注释的图像。测试和验证文件夹都包含 60 ...
12 月 27 日,中国市占第一的消费级 AR 品牌雷鸟创新发布大模型语音助手 Rayneo AI(beta 版),并通过雷鸟 X2 消费级真 AR 眼镜内测上线。

人脸盲复原是计算机视觉领域的一个重要课题,由于其广泛的应用而受到人们的广泛关注。在这项工作中,我们深入研究了利用预训练的稳定扩...

最近,Segment Anything Model (SAM) 已经展示出了强大的分割能力,在计算机视觉领域引起了广泛关注。基于预训练的 SAM 的大量研究工作...

自动驾驶车辆(AVs)必须准确检测来自常见和罕见类别的物体,以确保安全导航,这催生了长尾3D目标检测(LT3D)的问题。当代基于激光雷达...

前几日,有消息报道,苹果已开始为 Apple Store 员工安排 Vision Pro 的培训课程。

近两月有关 Pico 公司裁员消息在行业内频传。 首次传闻为: Pico 业务将关停,裁员范围超 80%,涉及公司上千人。 11 月 8 日,Pico 在微...

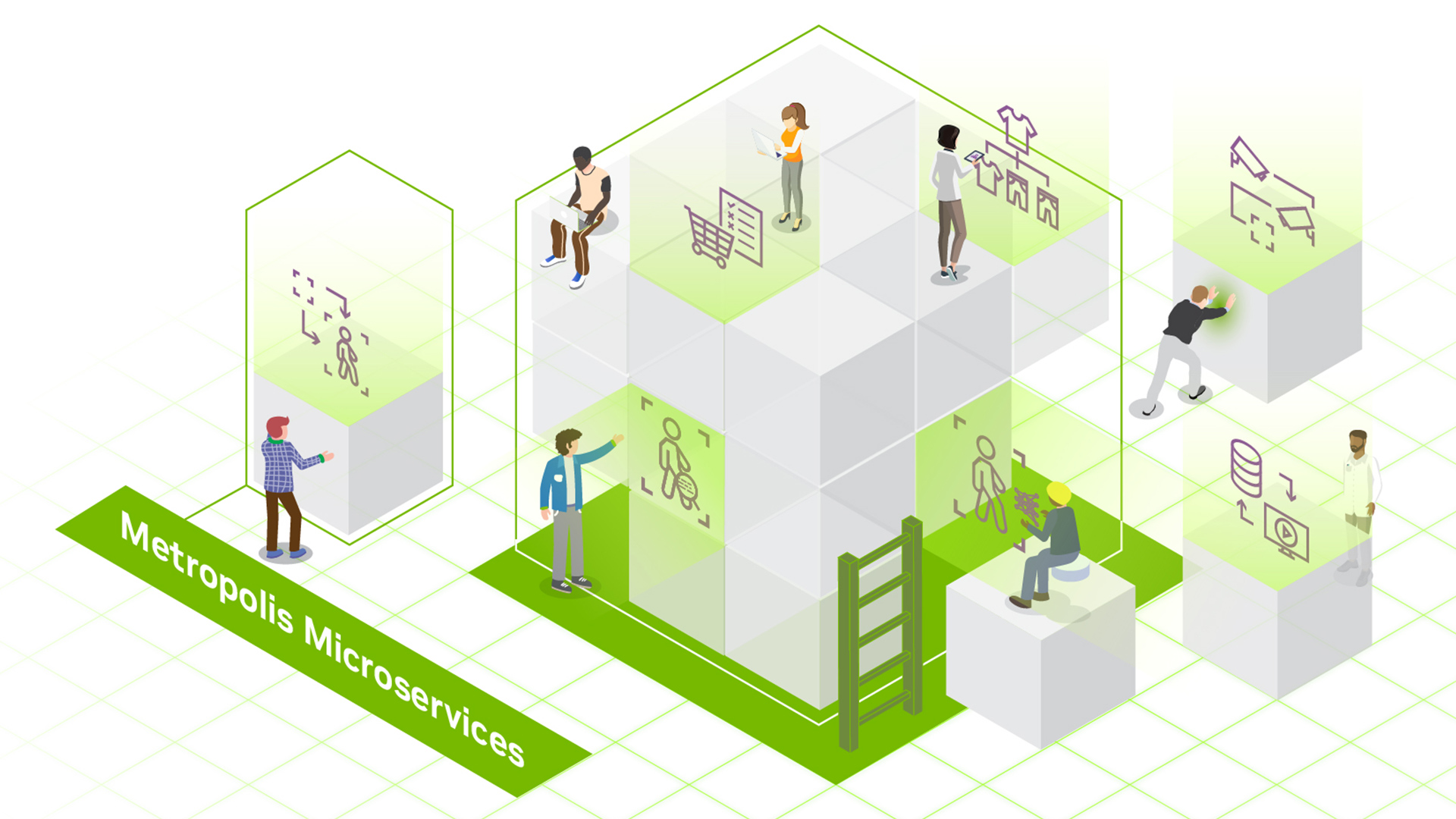
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上...

据 12 月 18 日外媒消息,苹果公司今年 9 月份刚刚推出的 Apple Watch Series 9 和 Apple Watch Ultra 2 因陷入了专利纷争而将在本周开...

通过一个统一的框架,GLEE可以在开放世界场景中完成任意物体的检测、分割、跟踪、接地和识别,以完成各种物体感知任务。

时至今日,「音频眼镜」仍受不少大厂商青睐,他们有像华为、小米一样的手机厂商,有像 Soundcore 一样的音频配件厂商,还有喜马拉雅一样...

作为 2023 年 Unity 收官活动,Unity Open Day 广州站将为开发者们带来众多精彩。

传统2D姿态估计模型受到其特定类别设计的限制,仅适用于预定义的对象类别。在处理新对象时,由于缺乏相关的训练数据,这一限制变得尤为...

在前不久武汉召开的魅族秋季无界生态发布会上,魅族的全新品牌 MYVU——唯我独见 It’s my view,正式亮相。两款可全天候时尚佩戴的 AR 智...