OpenCV中自带的模板匹配算法,完全是像素基本的模板匹配,特别容易受到光照影响,光照稍微有所不同,该方法就会歇菜了!搞得很多OpenCV...

LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,旨在训练能够处理和生成自然语言文本的大型模型。
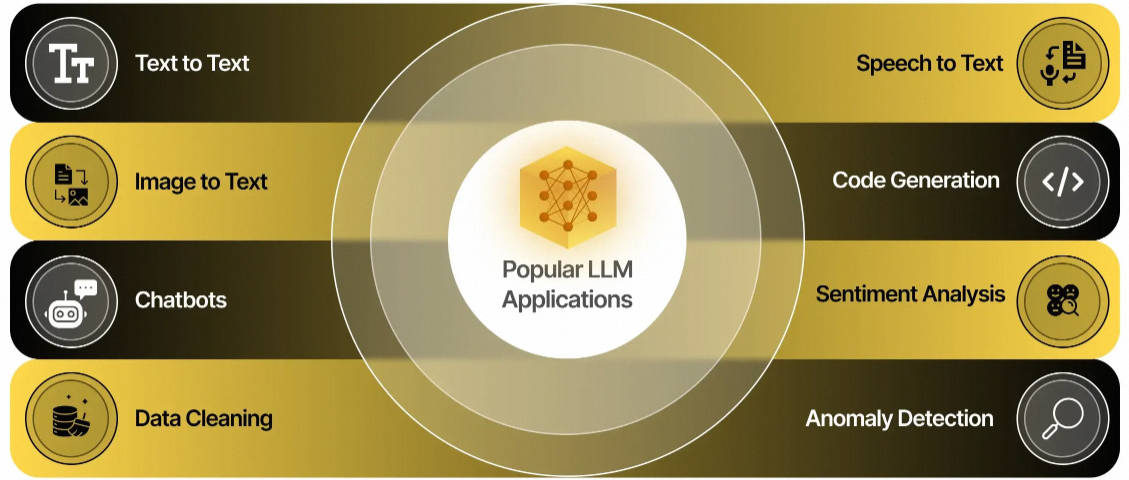
探索多模态语言模型整合了多种数据类型,如图像、文本、语言、音频等异质性。尽管最新的大型语言模型在基于文本的任务上表现出色,但它...

CogVLM 是一个强大的开源视觉语言模型(VLM)。CogVLM-17B 拥有 100 亿视觉参数和 70 亿语言参数。
计算机视觉在不同领域解决已成为解决实际问题的常用方法,如智慧农牧管理。这类场景并不需要每秒处理许多帧,此时树莓派这类单板主机就...
基于自定义数据集的咖啡豆颜色分类生成和cifar-100一样格式的数据集数据集有4类,分别为Dark,Green,Light,Medium上面这段代码可以生成tr...

本文的主题是多模态融合和图文理解,文中提出了一种名为RegionSpot的新颖区域识别架构,旨在解决计算机视觉中的一个关键问题:理解无约...

无意中从一个群里看到的一个截图,说是CodeFormer做的,搜索一下github发现了这个人脸修复的神器,github的地址如下:

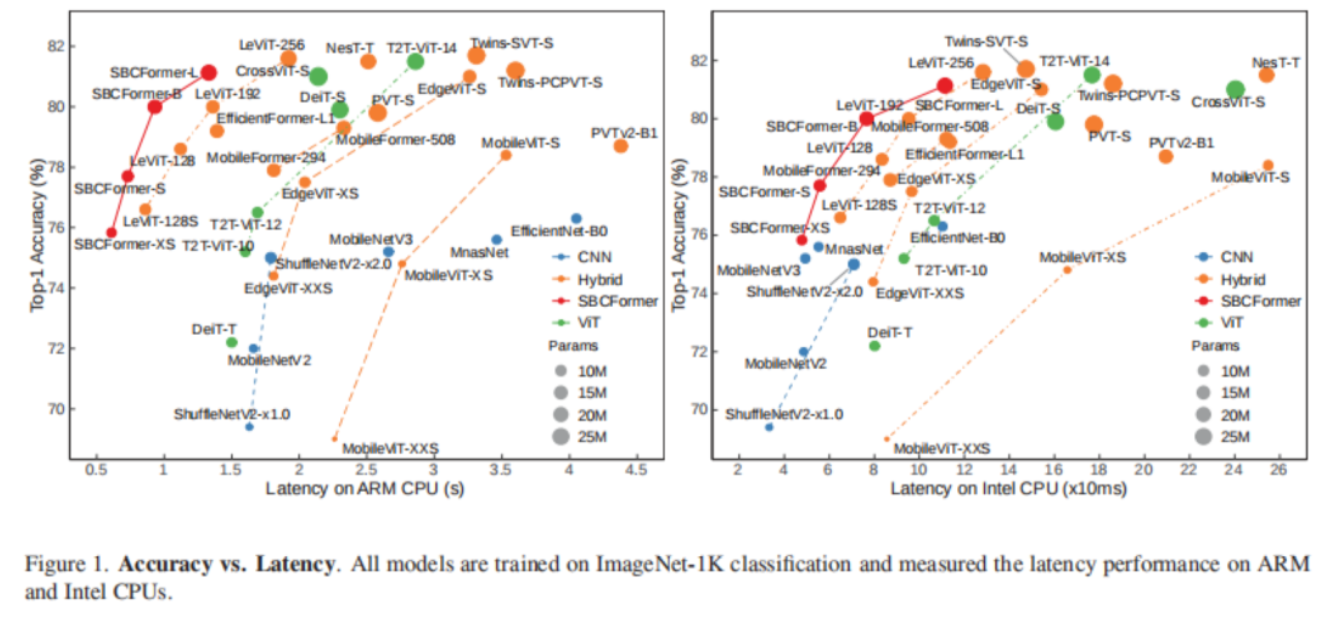
资源受限的感知系统,例如边缘计算和面向机器人视觉,要求视觉模型在计算和内存使用方面既准确又轻量化。虽然知识蒸馏是增强轻量级分类...

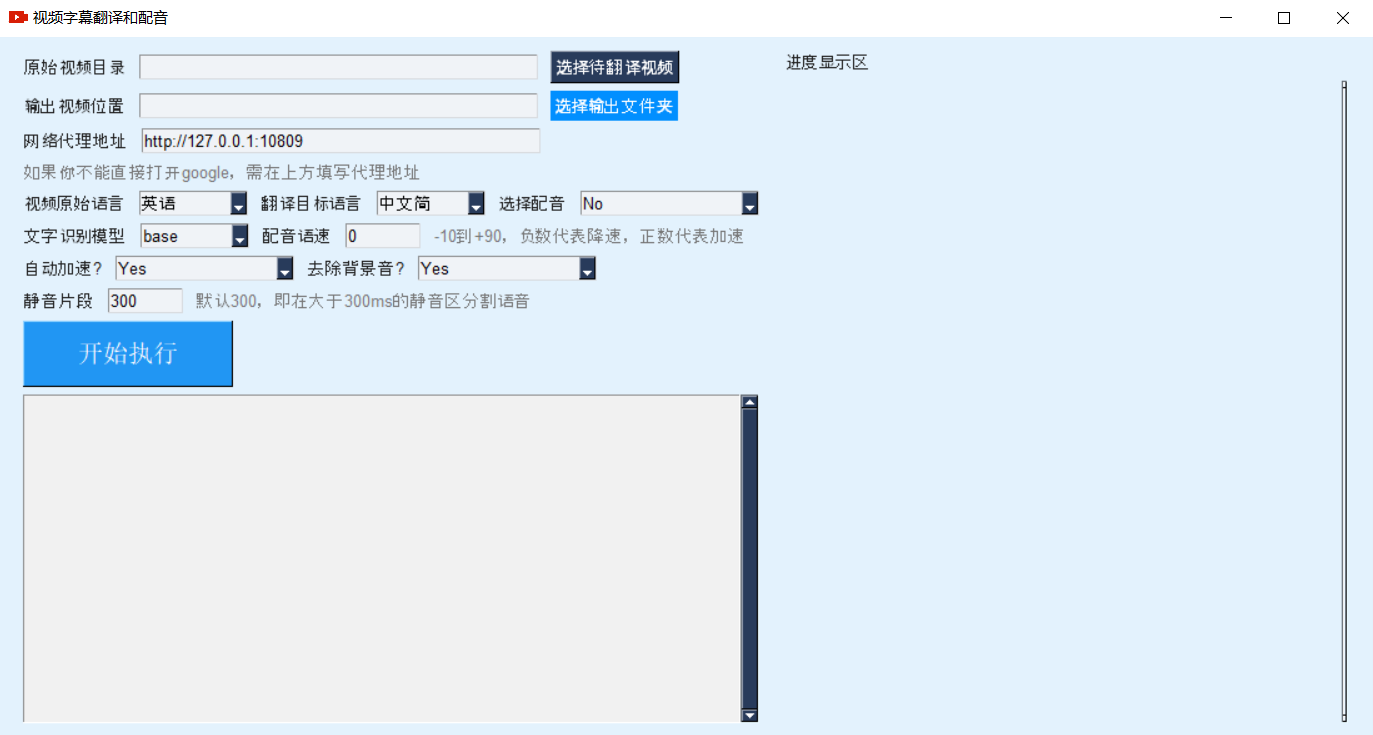
近来得空研究了下视频翻译,即将某种语言的视频处理后,显示另一种语言的字幕并使用该语言进行配音。最终实现了这种效果:
后来,我也曾去过很多城市,看过不少策划精良的展览。那场“穿越北宋”的名画之旅,依然是我看过的,最具沉浸感的一场文化类展演,没有之一。

作者提出了一种用于使用时间LiDAR点云进行3D目标检测的Late-to-Early循环特征融合方案。作者的主要动机是将具有目标感知能力的潜在嵌入...

背景收到试用套件有一段时间了,放假回来一直在调试另外一个项目,导致这个事情一直拖到现在还没搞完。在这里初步记录一下目前搞到的阶...

OpenAI要出手AI图像识别了。最新消息,他们公司正在开发一种检测工具。根据首席技术官Mira Murat透露:该工具精度非常高,正确率可达99%...

FaceChain是一个可以用来打造个人数字形象的深度学习模型工具。用户仅需要提供最低一张照片即可获得独属于自己的个人形象数字替身。Face...

在上一篇博文中,我们已经学会了使用工具生成自己需要的模型。接下来我们一起看看如何部署,模型在设备上。
据世界卫生组织统计,全球共 22 亿人视力受损,包含 2.85 亿视障人群和 3,900 万全盲人群。而且,这一数字将随老龄化加剧不断增加。 虽...

自从DETR发布以来,基于 Query 的目标检测器已经取得了显著的进展。然而,大多数现有方法仍然依赖于多阶段的编码器和解码器,或者两者的...

最近,端到端的目标检测器因其出色的性能而受到研究界的广泛关注。然而,DETR通常依赖于在ImageNet上进行Backbone网络的监督预训练,这...

交通标志是确保交通安全和顺畅通行的重要设施,但由于许多原因可能会受到损坏,这会带来很大的安全隐患。因此,研究一种检测损坏交通标...