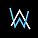TL;DR: 本文核心内容在于解决在暗光照射条件下进行物体检测的问题。作者建立了一个名为PE-YOLO的暗光物体检测框架,它将金字塔增强网络(...

最近,通用领域的大语言模型 (LLM),例如 ChatGPT,在遵循指令和产生类似人类响应方面取得了显著的成功,这种成功间接促进了多模态大模...
Title: Tracking Anything in High Quality PDF: [链接]Code: [链接]

本文聚焦于解决制约暗光算法应用的三个问题:训练集和现实暗光场景的退化特征的差异,现有的评价指标不能很好地衡量人眼感知质量,以及...

内容一览:近年来,全球气候变化形势严峻,由此引发的蝴蝶效应,正深刻地影响着人类和大自然。在这一背景下,收集数百甚至数千公里范围...

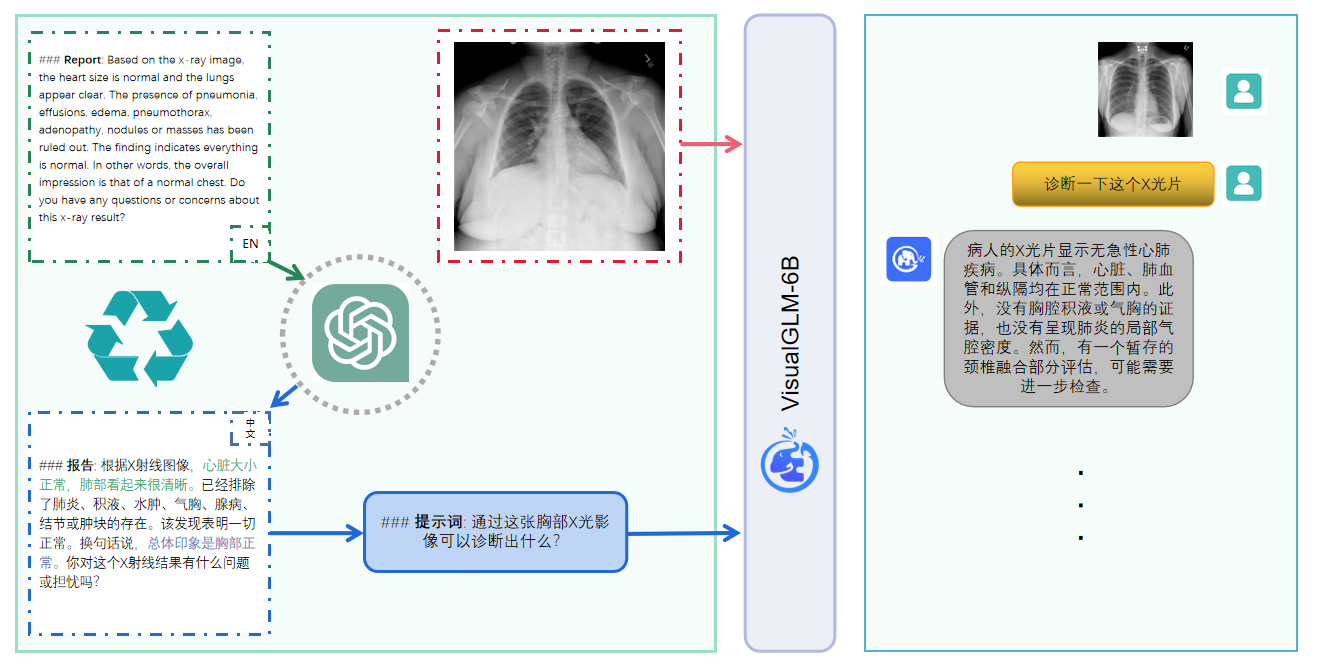
视频流的爆炸性增长为以高精度和低成本执行视频理解任务带来了挑战。传统的2D CNN计算成本低,但无法捕捉视频特有的时间信息;3D CNN可...
年初 CES 2023 展会上,宝马向我们展示了一台「新世代」车型:数字情感交互概念车 BMW i Dee。 在几十分钟的演示中,观众犹如在看一段科...

不久前,Hudl对外官宣了与微帧科技的合作,正式公布在其平台内融合微帧的WZ264及WZ265智能编码引擎,以提供更清晰的视频效果,帮助教练...
OCR(Optical Character Recognition,光学字符识别)是指对图像进行分析识别处理,获取文字和版面信息的过程,是典型的计算机视觉任务,通...

今天,中国的城市,在历经十余年的“智慧城市”建设后已经被赋予了数智融合的全新解读。随着近年来5G、云计算、人工智能爆发式能量增长,...

当前,Vision Transformer(ViT)在许多视觉任务中占据主导地位。通过Token稀疏化或降维(在空间或通道上)来解决其Token多Head自注意力...

作者发现Deep Convolutional Neural Networks (DCNNs) 能够很好的处理的图像级别的分类问题,因为它具有很好的平移不变性(空间细节信息...
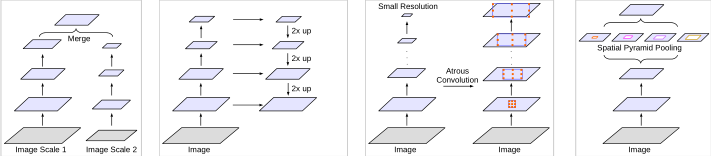
目前,计算机视觉是深度学习领域最热门的研究领域之一。从广义上来说,计算机视觉就是要“赋予机器自然视觉的能力”。实际上,计算机视觉...

对计算机而言,能够“看到”的是图像被编码之后的数字,它很难理解高层语义概念,比如图像或者视频帧中出现的目标是人还是物体,更无法定...

相较于VGG的19层和GoogLeNet的22层,ResNet可以提供18、34、50、101、152甚至更多层的网络,同时获得更好的精度。但是为什么要使用更深...

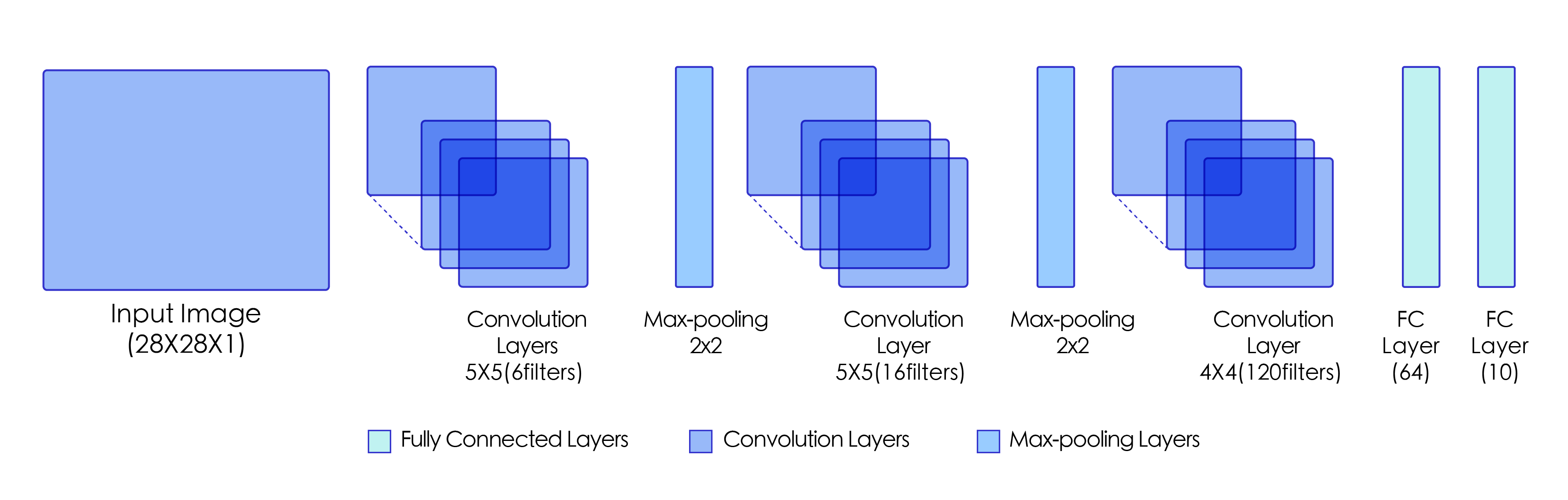
LeNet是最早的卷积神经网络之一[1],其被提出用于识别手写数字和机器印刷字符。1998年,Yann LeCun第一次将LeNet卷积神经网络应用到图像...
传统上,卷积神经网络(CNN)和Vision Transformer(ViT)主导了计算机视觉。然而,最近提出的Vision Graph神经网络(ViG)为探索提供了...

人工智能领域:面试常见问题超全(深度学习基础、卷积模型、对抗神经网络、预训练模型、计算机视觉、自然语言处理、推荐系统、模型压缩...

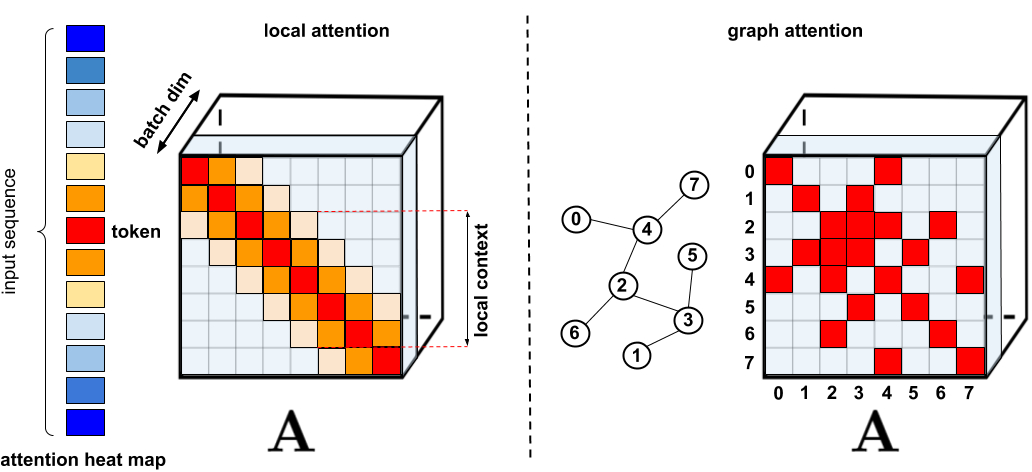
基于Transformer模型在众多领域已取得卓越成果,包括自然语言、图像甚至是音乐。然而,Transformer架构一直以来为人所诟病的是其注意力...
本文首发于 CVHub,白名单账号转载请自觉植入本公众号名片并注明来源,非白名单账号请先申请权限,违者必究。