10月27日,华为发布2023年前三季度经营业绩简报,报告期内实现销售收入4566亿元人民币,同比增长2.4%,净利润率为16.0%。对于各业务板块...
最近,业界首个以算网融合为核心的多元算力研究报告《算力经济时代·2023新型算力中心调研报告》出版,我们将对报告内容开启连载模式。

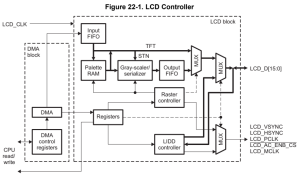
要实现一块LCD正常的显示文字、图像和触摸,不仅需要LCD驱动器,而且还需要相应的LCD控制器,控制器一般有两种:显示控制器和触摸控制器...
商汤高性能计算 (HPC) 团队秉承开源之心,与北京科学智能研究院 (AI for Science Institute, Beijing)的 DeepFlame团队合作,助力 DeepM...

集微网消息,随着云计算、物联网等人工智能技术的发展,传统表计行业也在不断的发生变化,逐渐往智能表计方向转型,智能表计迎来了高速...
为何随着半导体行业进入供过于求周期,消费级显卡价格仍在上涨?为何游戏作为显卡最初的应用,发展到现在游戏显卡反而越来越不香了?本...
早在UE3时代,就已经通过节点图支持了VR的渲染,其中渲染管线的不同组件可以在多个配置中重新排列、修改和重新连接。根据所支持的节点类...
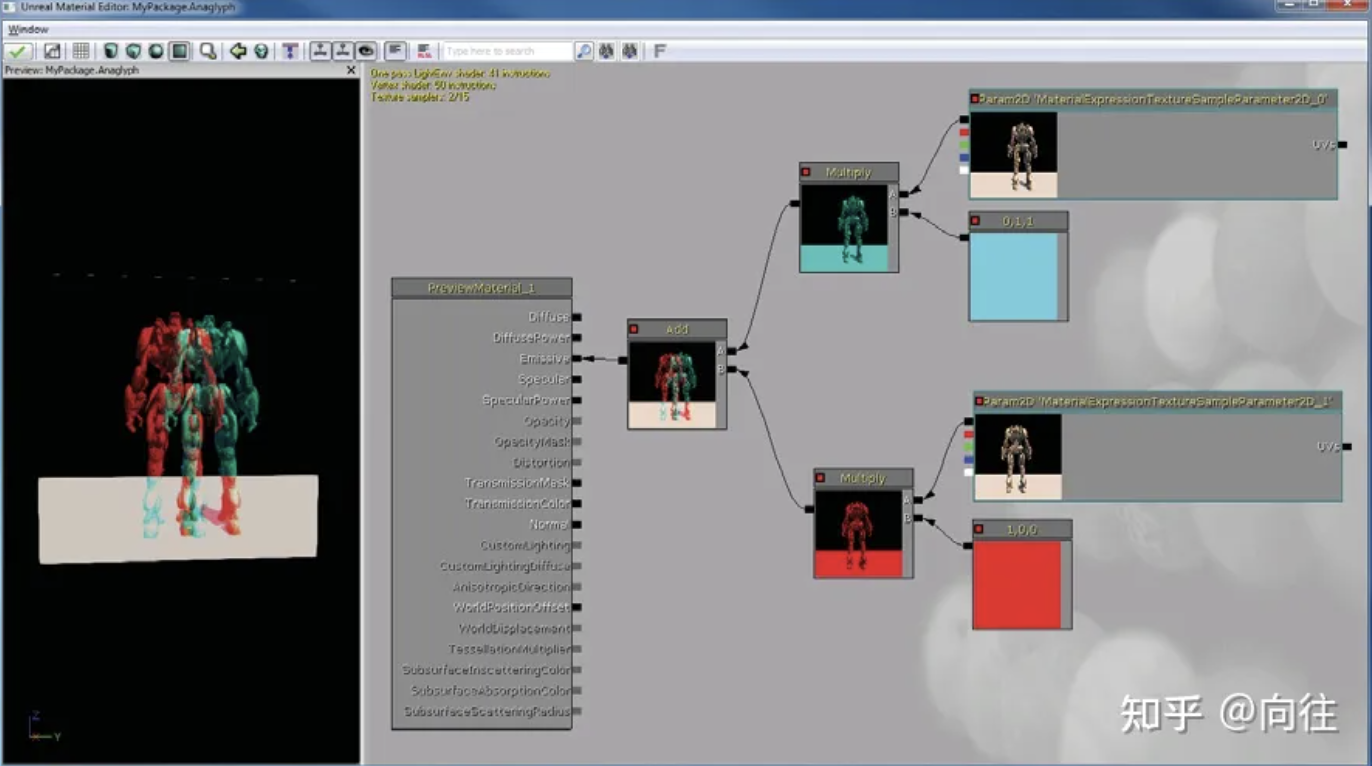
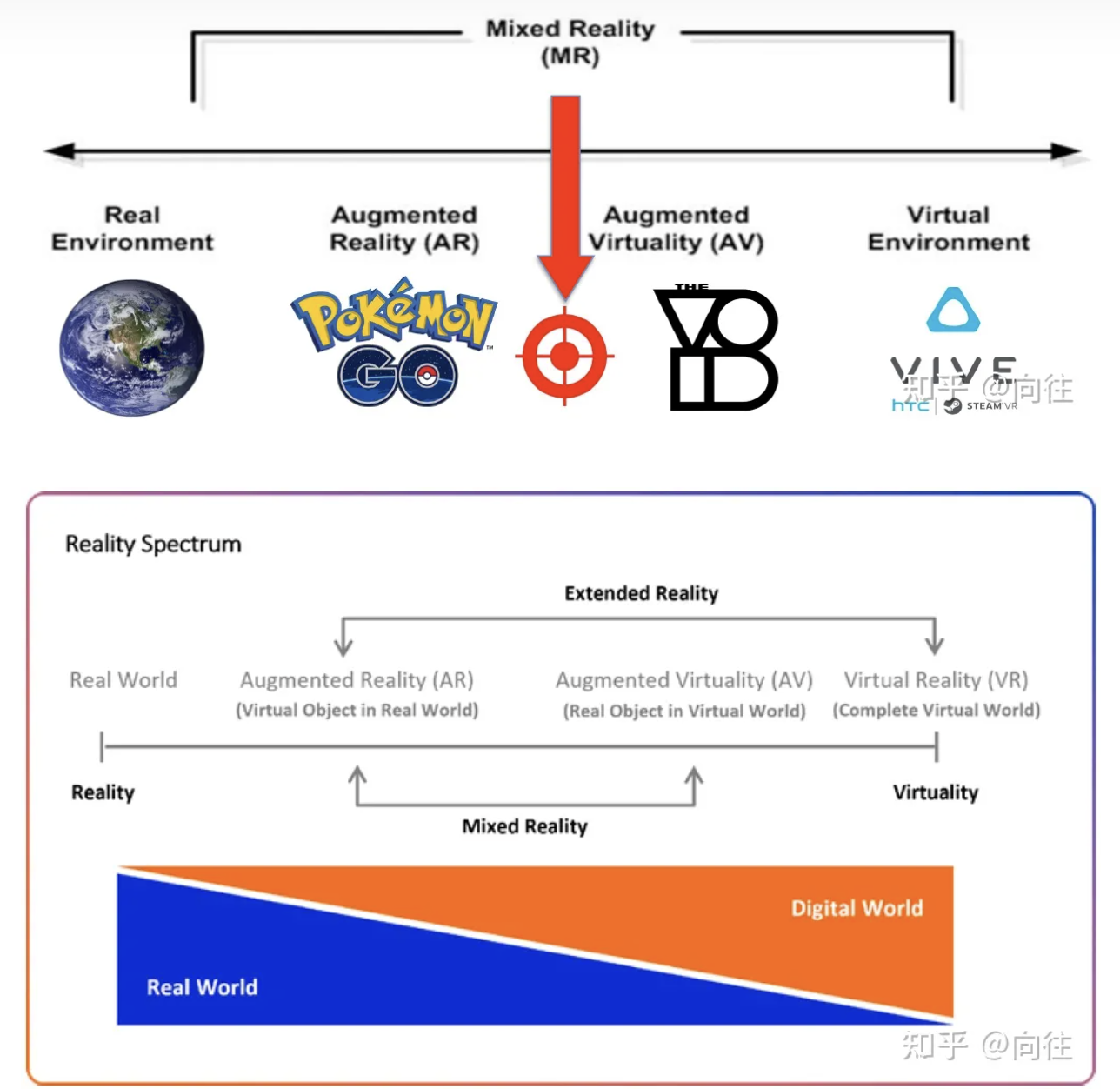
虚拟现实(VR)因伊万·萨瑟兰(Ivan Sutherland)在20世纪60年代的工作而广受赞誉。在过去的50年里,虚拟现实技术的普及程度上下波动。...
在工作站面向的用户群中,第一大行业是制造业(包括CAD/CAE),第二大是媒体和娱乐(DCC,数字内容创作)。这2大行业都会有渲染的需求,...
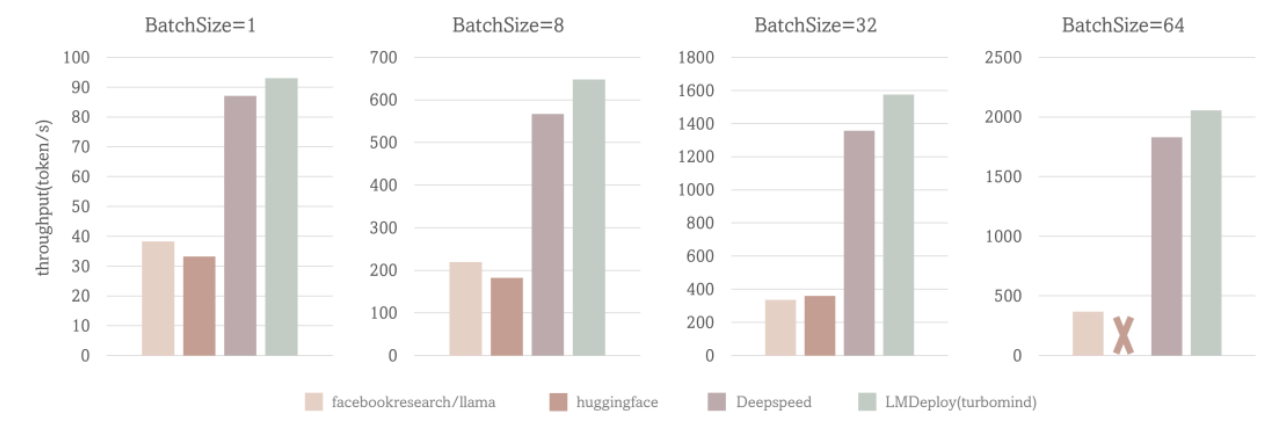
今天要介绍的是 lmdeploy,一个服务端场景下、transformer 结构 LLM 部署工具。
写这个源自我在清华同窗一个技术八卦群聊起了nvlink的若干技术,然后就打算写一写我作为一个旁观者所见并试图还原的nvlink的历史。
集微网消息,据Business Korea报道,全球客户一直在排队购买英伟达的图形处理单元(GPU),但供应紧张导致价格飙升。GPU是生成人工智能(AI...
集微网消息,据BusinessKorea报道,英伟达的AI图形处理单元(GPU)占据市场90%以上的份额,目前供不应求,价格飙升。而英伟达用于ChatGP...
五月的最后一天,从GPU(图形处理器)战场成长起来的芯片制造商英伟达,凭借着对数据中心业务的乐观预期,市值突破万亿美元,成为美国第...
作为国内领先的信息技术核心产品研发企业,龙芯中科致力于打造自主开放的软硬件生态和信息产业体系,为国家战略需求提供自主、安全、可...

2023年5月30日,为期4天的台北国际电脑展(COMPUTEX)在台湾省台北市开幕,众多厂商都携自家的最新产品参展,其中NXP在本届展会上带来了...

风火轮近来又推出一款新的嵌入式主板YY3568,它是一款基于瑞芯微RK3568 4核处理器的ARM主板,性价比极高;现在瑞芯微的旗舰款是rk3588主...

3月31日,网络安全审查办公室发布公告称,对美光公司(Micron)在华销售的产品实施网络安全审查。

Vertex处理,做MPV(Model,View, Project trasform)和Screen mapping坐标变换,clip裁剪
新款Arm®Immortalis™ - G715 GPU及其较小的兄弟产品Arm Mali现在可以在消费类设备中使用,开发者可以访问。每一代Arm GPU都会带来改进,...
















