首发:AIWalker作者:HappyAIWalker标题&作者团队paper: [链接]code: [链接]本文是港理工&达摩院张磊团队在image-to-image translation...

在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点...
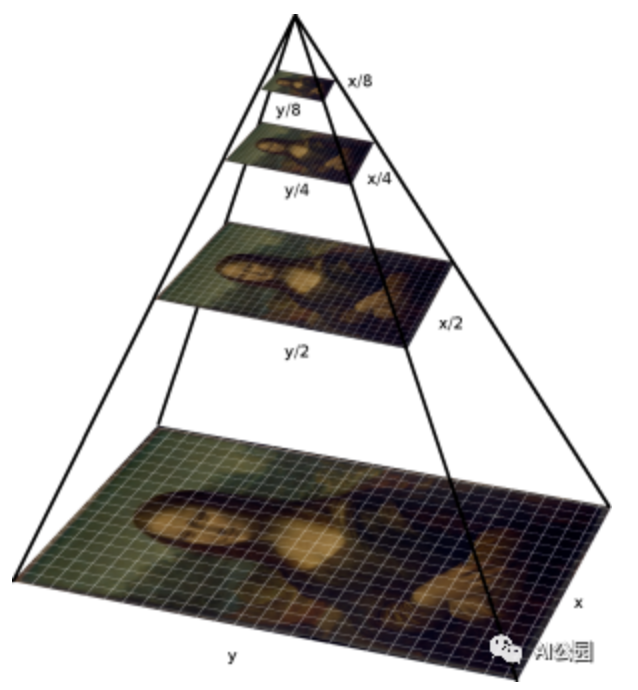
转载于:GiantPandaCV作者: zzk引言目前Transformer应用到图像领域主要有两大挑战:视觉实体变化大,在不同场景下视觉Transformer性能...

首发:AI公园公众号 作者:Gidi Shperber编译:ronghuaiyang导读OCR中的研究,工具和挑战,都在这儿了。介绍我喜欢OCR(光学字符识别)。...

2018 年,印度国家转型委员会发布的报告中指出,印度地区法院、高级法院、最高法院中,堆积的未审结案件数量,已经超过了 2900 万。

FinRL-Libray 项目:[链接]选择FinRL镜像在矩池云-主机市场选择合适的机器,并选择FinRL-Library镜像。登录服务器在租用列表中查看服务...

本文是旷视科技&快手科技&电子科大联合提出的一种新颖的图像超分框架。本文从图像超分“病态”特性出发,提出一种两阶段的超分框架。在div...

由香港大学CVMI Lab和牛津大学合作提出了一种点云上具有动态内核组装的位置自适应卷积——PAConv: Position Adaptive Convolution with Dy...

开始学习深度学习的话,框架的选择是个很重要的事情(毕竟调包的居多)。这么多框架我们怎么选择,跟着谷歌的TensorFlow?不对,学长说学...

导读:本期为 AI 简报 20210416 期,将为您带来 7 条相关新闻~本文一共 2300 字,通篇阅读结束需要 5~8 分钟

网上有大量的YoloV5教程,本文的目的不是复制内容,而是对其进行扩展。我最近在做一个目标检测竞赛,虽然我发现了大量创建基线的教程,...

本文是华为诺亚、清华大学以及悉尼大学提出的一种用于高效图像超分的频率感知动态网络。本文从图像的不同频率成分复原难度、所需计算量...

【GiantPandaCV导语】本文基于Pytorch导出的ONNX模型对TVM前端进行了详细的解析,具体解答了TVM是如何将ONNX模型转换为Relay IR的,最后...

对中国很多区域城市而言,“要致富,先修路”这句过去经常能看见的标语,在今天仍然有着巨大的价值意义。但此时,这条“路”已经不再是有形...
本文提出了一个更深更轻的Transformer,DeLighT,它的性能与Transformer相似,甚至更好,平均少了2到3倍的参数。

在本文中,我将解释上一篇文章中称之为“2 class filter”的概念。这是一种用于目标检测和分类模型的综合技术,在过去几周我一直在做的Kag...

最近Google出了一篇关于超大模型pipeline并行训练的论文《_TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Lang...
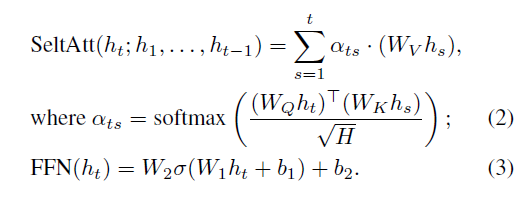
今天给大家介绍一下FPGA上部署深度学习的算法模型的方法以及平台。希望通过介绍,算法工程师在FPGA的落地上能“稍微”缓和一些,小白不再...

首发:AIWalker作者:HappyAIWalker标题&作者团队paper:[链接]code:[链接]本文是国防科大的王龙光等人关于盲图像超分的最新工作,已被...

使用每个类的有效样本数量来重新为每个类的Loss分配权重,效果优于RetinaNet中的Focal Loss。