API 综合套装,包含高性能工具、样本和文档,适用于 Windows 和 Linux 的硬件加速型视频编码和解码。

Query-based Transformer 在许多图像域任务中显示出构建远程注意力的巨大潜力,但由于点云数据的庞大规模,在基于 LiDAR 的 3D 目标检测...

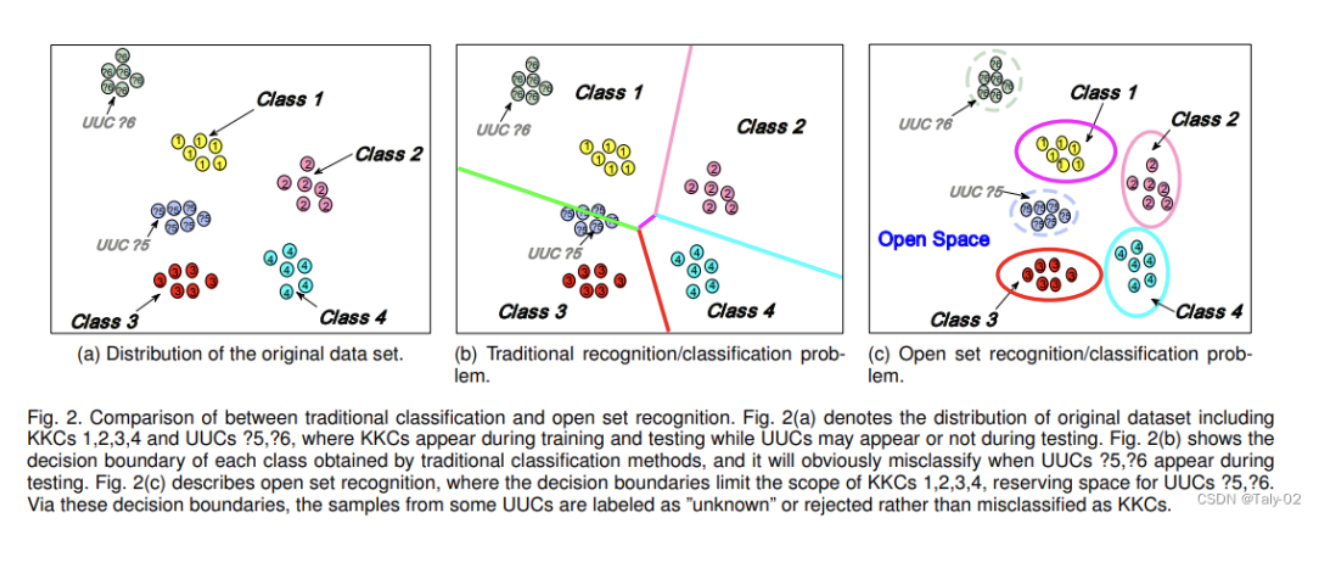
标题:Open-Set Recognition: a Good Closed-Set Classifier is All You Need?
NVIDIA OptiX 光线追踪引擎用于在 GPU 上实现出色光线追踪性能的应用框架,提供简单、递归式的灵活工作流,用于加速光线追踪算法。它包...

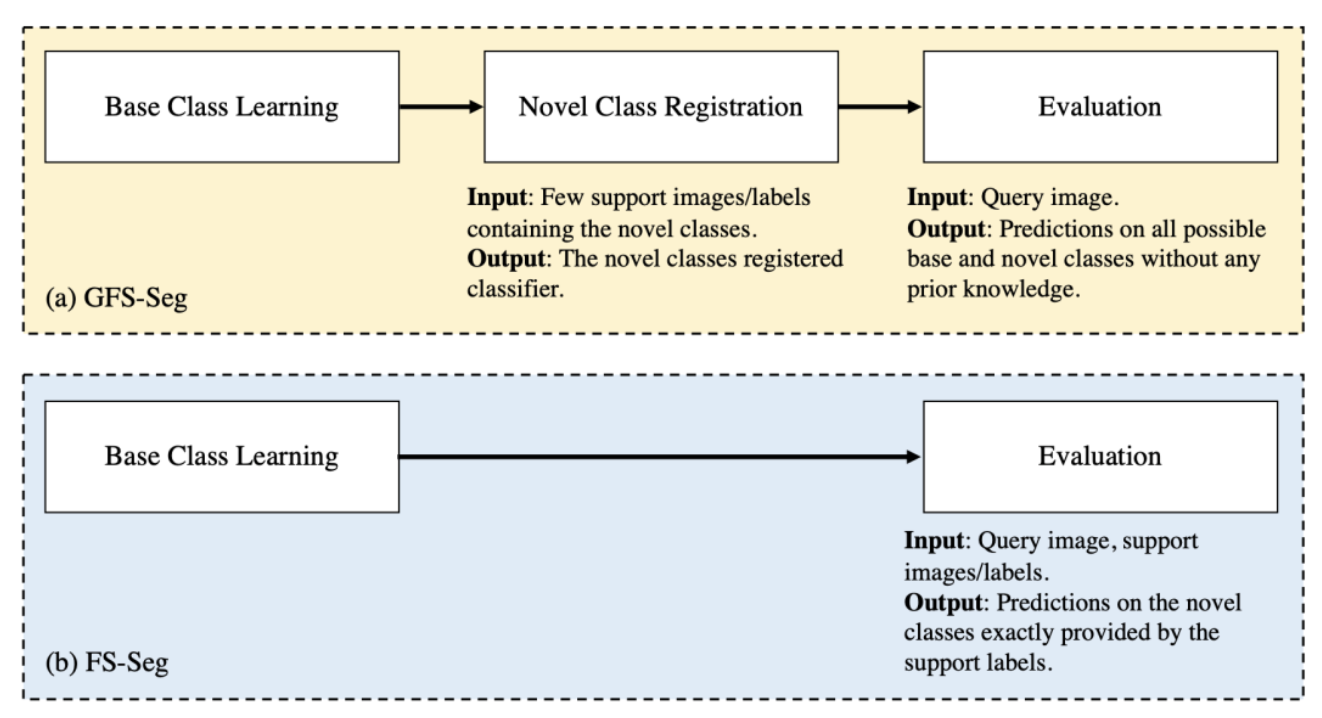
文章目录1 前言2 概述3 GFS-Seg 和 FS-Seg 的 Pipeline 区别4 Towards GFS-Seg5 上下文感知原型学习(CAPL)6 实验7 结论8 参考链接1 前...
H.265/HEVC作为ITU-T VCEG继H.264/AVC之后所制定的新视频编码标准,能够在有限带宽下传输质量更高的视频。超高清视频的普及与流行,使得...

多年来,YOLO 系列一直是高效目标检测的行业标准。YOLO 社区蓬勃发展,丰富了其在众多硬件平台和丰富场景中的使用。在这份技术报告力求...

YOLOU是一个集成YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOv7、YOLOX以及YOLOR的YOLO系列目标检测算法库,对于轻量化目标检测同时也集成了YO...

outdoor LiDAR 点云中的前景点(即物体)和背景点之间经常存在很大的不平衡。它阻碍了检测器专注于信息区域以产生准确的 3D 目标检测结...

我们生活在一个日益数字化的世界里,虚拟现实和增强现实等技术正在改变着我们与世界的交互方式。 越来越多的「数字人」诞生,在虚拟数字...

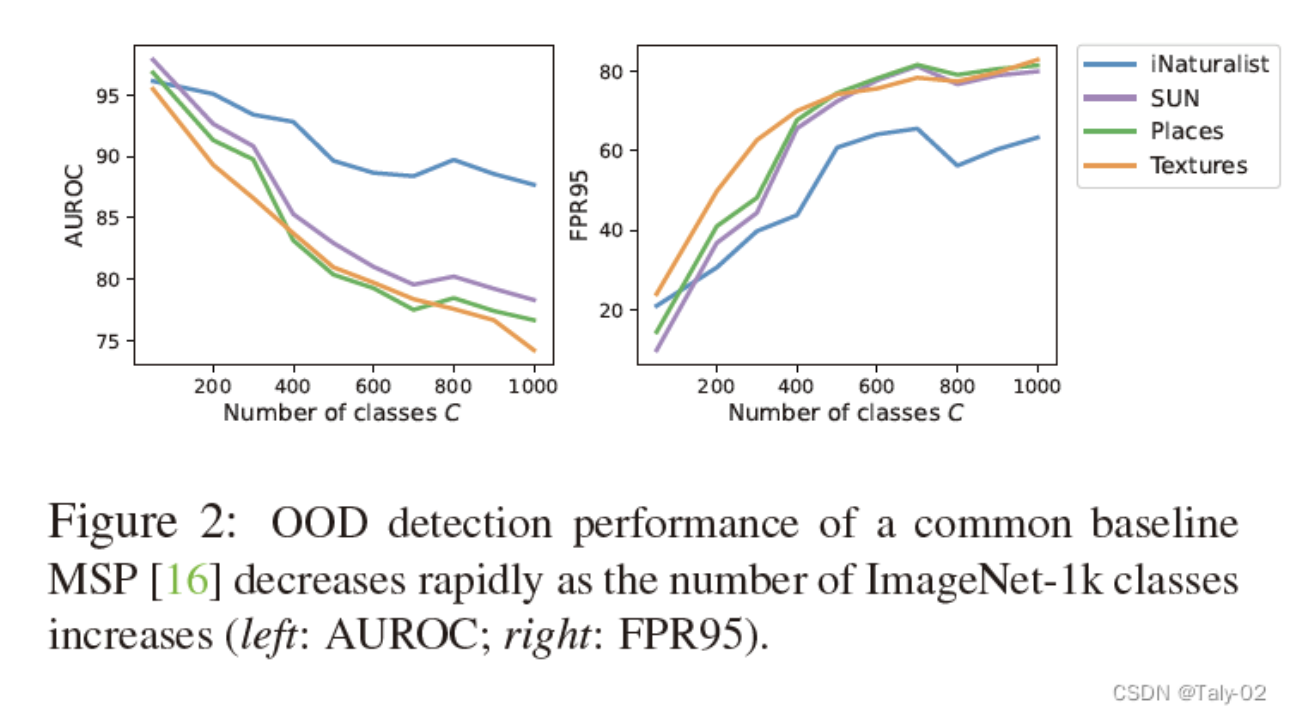
MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space CVPR 20221. 论文信息标题:MOS: Towards Scaling Out-...
特征金字塔网络 (FPN) 一直是目标检测模型考虑目标的各种尺度的基本模块。但是,小目标的平均精度(AP)相对于中大目标的平均精度(AP)...

NVIDIA 材质定义语言(MDL)可让您在支持的应用程序之间自由地共享基于物理性质的材质和光源。例如,在 Allegorithmic Substance Design...

在过去的十年中,多任务学习方法在解决全景驾驶感知问题方面取得了不错的成果,同时提供了高精度和高效率的性能。在为计算资源有限的实...

“云游戏” 的概念早在十多年前就已被提出,承载着行业和万众的期待。尽管云游戏本身具有 “云端运行、超高清、零延时、即点即玩” 等众多特...

语义分割是医学图像计算中最热门的研究领域之一。尽管 nnU-Net 的概念化可以追溯到 2018 年,但它继续为各种分割问题提供具有竞争力的开...

上周 8 月 16 日,市场调研机构 Strategy Analytics 发布了一份有关于消费级 AR 终端市场报告。

今晚(8 月 23 日),消费级 AR 眼镜品牌 Nreal 在京召开中国首场 AR 眼镜发布会,面向中国市场正式推出三款硬件产品,其中包括:

在滤波、变换、缩放等任务中,图像分割具有重要的意义。图像分割是将不同的对象划分为不同的部分,并将这些区域以明显的颜色或者记号标...

尤其是近两年三星在国内举办的 S 系列、Z 系列发布会,无论从发布会场地选择、展区设计,还是舞美、流程编排设计,都呈现出极佳的观感。

检测微小目标是阻碍目标检测发展的主要障碍之一。通用目标检测器的性能往往会在微小目标检测任务上急剧下降。在本文中指出,Anchor-Base...

yolov5-6.2增加了分类训练、验证、预测和导出(所有 11 种格式),还提供了 ImageNet 预训练的 YOLOv5m-cls、ResNet(18、34、50、101) ...

直播已深入每家每户,以淘宝的直播为例,在粉丝与主播的连麦互动中如何实现无感合屏或切屏?阿里云GRTN核心网技术负责人肖凯,在LVS2022...
据海外咨询机构 Counterpoint 在 5 月份发布的数据报告,在 2021 年底,Meta Quest 2 出货量即已超过了 1000 万台。

两款新品在镜面视觉、AI 技术、影音体验等方面进行了迭代升级:搭载了新一代 NPU 处理器,自研的运动分析引擎 FITURE Motion Engine 2.0...

在最近的一次电视合作伙伴闭门会中,Google 谈起了自己的新计划,希望将可穿戴设备与电视平台做更好的集成,为用户构建客厅交互式健身娱...

腾讯AI Lab在2020年的paper,核心思想就是利用2D手部关键点标注生成语义分割标注,监督一个语义分割分支,并把该分支的特征图拼接到姿态...

8 月 10 日,五菱汽车宣布,与大疆车载深度融合的「灵犀智驾系统」正式发布。据悉,该系统基于上汽通用五菱「情绪引擎」理念打造,聚焦...

在 8 月 11 日的小米秋季新品发布会上,在最后的 One More Thing 环节,已经演讲了两个小时的雷军,向米粉们汇报了小米汽车的最新进展,...

卷积神经网络 (CNN) 在许多计算机视觉任务(例如图像分类和目标检测)中取得了巨大成功。然而,它们的性能在图像分辨率低或目标很小的任...



 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西













