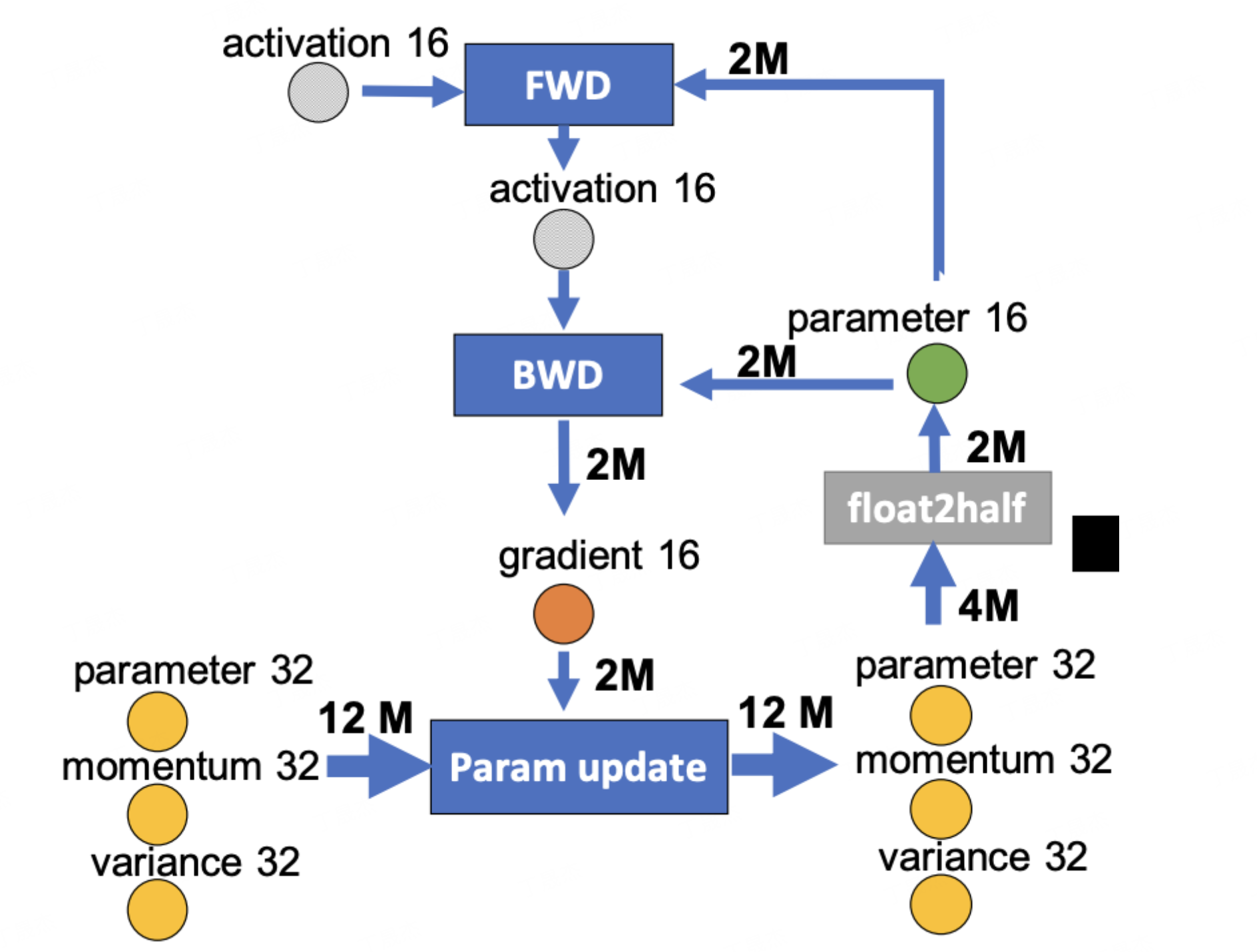
本文介绍来自华为诺亚方舟实验室、清华大学和香港中文大学联合在大语言模型量化上的最新工作 FlatQuant (Fast and Learnable Affine Tra...

大家好,今天我们继续vllm源码的解析,一起来看下它最近总是被频繁提起、也是较不好理解的一个创新点:Prefix Caching(本文同时也是Blo...

本文介绍了瑞莎星睿 O6 (Radxa Orion O6) 开发板通过 Ollama 工具实现 DeepSeek 语言大模型的本地部署。

关于此芯Armv9 AI PC开发套件瑞莎“星睿O6”评测第二期,经过严格的评估和筛选,最终试用测评名单已公布如下,恭喜各位开发者!安谋科技会...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...

聆思全新一代六合一芯片「LS26系列」,搭载WIFI / BLE & BT / NPU,与「小聆AI」强强联合,将碰撞出怎样的智能火花?关注并私信获得内测...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
近年来,大型语言模型 (LLM) 在医疗问诊中的应用越来越受到关注。在湖南省湘潭市雨湖区昭潭街道社区卫生服务中心,家庭医生刘彦博正根据...
然而,在深海勘测任务中,面对海量且复杂的海洋数据,传统的计算方法显得力不从心,迫切需要高效数据处理与分析能力的支持。

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...

摘要:智能算力产业的ESG表现正成为衡量其高质量发展的核心指标。环境维度上,“东数西算”工程通过设定PUE硬性目标推动绿色算力发展,2023...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
医学领域的知识体系建立在数千年的发现与积累之上,涵盖了海量的原理、概念及实践规范。将这些知识有效适配到当前大语言模型有限的上下...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
随着大模型技术的快速发展,业界的关注点正逐步从模型训练往模型推理转变。这一转变不仅反映了大模型在实际业务中的广泛应用需求,也体...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
毫无疑问,在推进中国式现代化的宏伟征程中,工业数智化转型是必由之路。而工业软件,特别是新一代工业设计软件,早已突破传统工具软件...
2025年上半年,复杂多变的国际经济和贸易环境加剧了中国企业的经营压力,需求不足、产能过剩与利润下滑成为普遍挑战。

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
在过去的数年中,全球公共卫生安全面临严峻挑战。尤其自新冠疫情爆发以来,其病原体——严重急性呼吸综合征冠状病毒 2 型(SARS-CoV-2)持...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
7月26日,2025世界人工智能大会(WAIC)在上海开幕,这场被誉为“AI春晚”的盛会,不仅是各大厂商展示前沿技术的舞台,更是洞察AI产业脉动...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
AI-Compass将为你和社区提供在AI技术海洋中航行的方向与指引。无论你是刚踏入AI领域的初学者,还是寻求技术突破的进阶开发者,都能在这...
蛋白质侧链构象(Protein sidechain conformation),是指蛋白质中氨基酸残基的侧链在三维空间中的具体空间排布方式。研究蛋白质侧链构...

AI-Compass将为你和社区提供在AI技术海洋中航行的方向与指引。无论你是刚踏入AI领域的初学者,还是寻求技术突破的进阶开发者,都能在这...
在当今科学研究与工业应用的前沿领域,原子系统三维结构的生成建模正展现出颠覆性潜力,有望彻底重塑新型分子和材料的逆向设计版图。从...



 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西


















