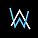前段时间一直在弄golang,很少关注一些开源项目。正巧碰到一个,可以将模糊的照片或者视频修复清晰,且可以超分处理的项目。

计算机视觉是深度学习领域最热门的研究领域之一,目前在各领域应用广泛,而它是如何发展至今,让我们一起回顾一下计算机视觉的发展史。

随着卷积神经网络在目标检测任务上的推进,它也开始被用于更精细的图像处理任务:语义分割和实例分割。目标检测只需要预测图像中每个对...

AiStudio是一个很好的学习平台,我相信无时无刻都有很多像我一样的小白出于对人工智能的兴趣,而汇聚在这里。这一次,我想做一个入门级...

PeleeNet: An efficient DenseNet architecture for mobile devices
近期,高效的视觉 Transformer 在资源受限的设备上展现出优异的低延迟性能。传统上,它们在宏观层面上采用4×4的块嵌入和4阶段结构,同时...

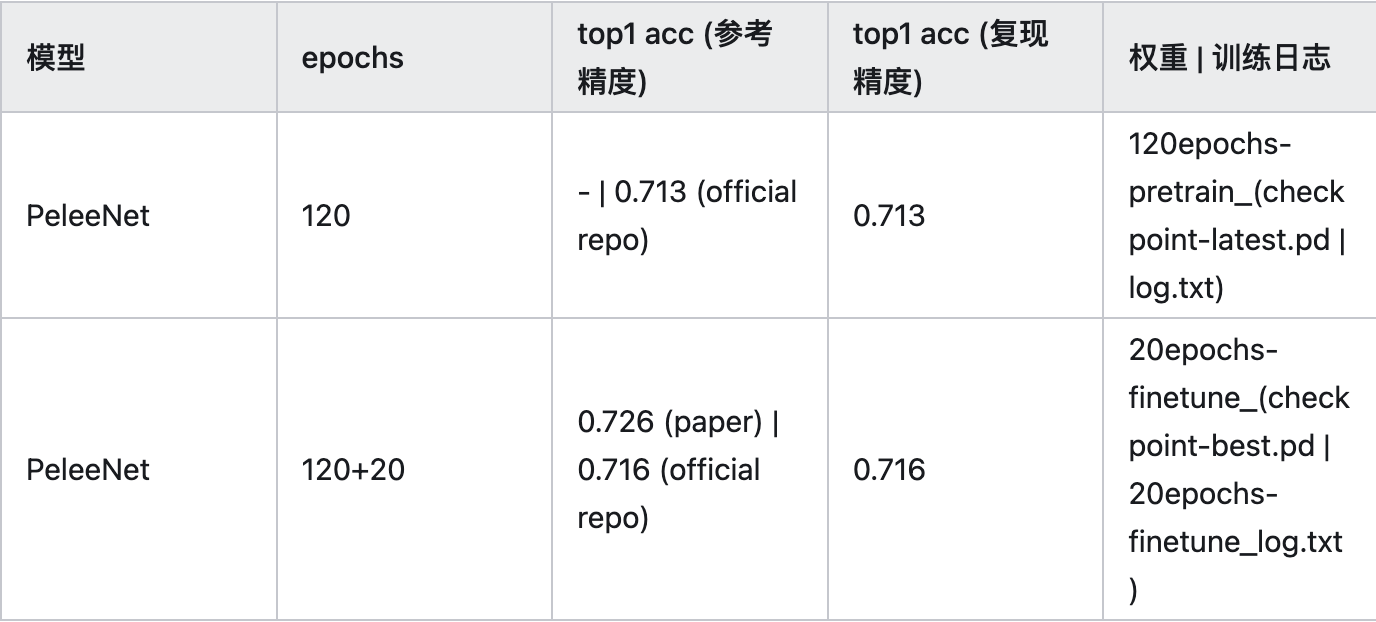
LSTM是一种RNN模型。RNN和CNN可以是DL的两种重要模型。CNN主要处理空间结构数据,RNN主要处理时间序列数据。但也不是绝对,本文中用作pr...
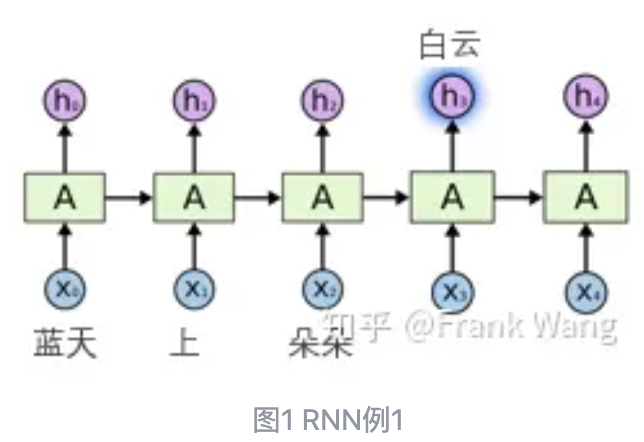
PointNet是斯坦福大学研究人员提出的一种点云处理网络,其可以直接输入无序点云集合进行处理,而不像基于投影的方法需要先对点云进行预...
ResNeXt是由何凯明团队在2017年CVPR会议上提出来的新型图像分类网络。ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的...

采用kaggle上的猴子数据集,包含两个文件:训练集和验证集。每个文件夹包含10个标记为n0-n9的猴子。图像尺寸为400x300像素或更大,并且...
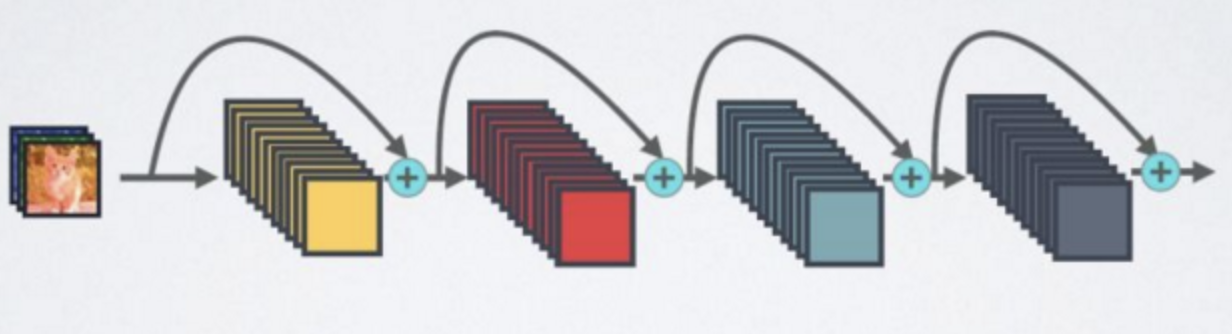
这里结合网络的资料和DenseNet论文,捋一遍DenseNet,基本代码和图片都是来自网络,这里表示感谢,参考链接均在后文。
得益于基础模型的发展,红外小目标检测(ISTD)算法取得了显著进展。特别是,结合卷积网络和 Transformer 结构的模型能够很好地提取局部...

随着移动计算技术的迅速发展,在移动设备上部署高效的目标检测算法成为计算机视觉领域的一个关键研究点。本研究聚焦于优化YOLOv7算法,...

大型语言模型构建在基于Transformer的架构之上来处理文本输入, LLaMA 系列模型在众多开源实现中脱颖而出。类似LLaMa的Transformer可以用...

春节假期耽误了些许时间,原定的项目因为一些原因被暂时搁置了 聆思CSK6 语音视觉多功能开发套件主打一个视觉和显示交互,这里决定先试...

助力海洋经济发展,微帧与陆海科技达成合作,在窄带网络环境下对视频进行实时极致编码压缩,提升视频画质,进一步促进航海安全。

研讨会安排主题:使用适用于 NVIDIA Jetson 的微服务加速边缘 AI 开发时间:2024 年 3 月 6 日(周三)凌晨 0:00 - 1:00(北京时间)边...
在像自动驾驶(AD)这样的安全关键领域,目标检测器的错误可能会危及行人和其他脆弱的道路使用者(VRU)。由于常见的评估指标不能充分指...

玉兔辞旧岁,金龙启新程。甲辰龙年正月初二,以“龙兴九州 福聚四海”的主题,打造戏曲表达新样态,传递戏曲文化氛围的《2024年春节戏曲晚...

由于在AI生成视频的时长上成功突破到一分钟,再加上演示视频的高度逼真和高质量,Sora立刻引起了轰动。在Sora横空出世之前,Runway一直...

NVIDIA Metropolis 微服务提供功能强大且可自定义的云原生 API 和微服务,用于开发视觉 AI 应用和解决方案。该框架现在涵盖 NVIDIA Jets...

边缘视觉 AI 应用的开发周期往往漫长且昂贵。同时,快速开发灵活、安全的云原生边缘 AI 应用的重要性也变得前所未有。现在,全新 NVIDIA...
在Transformer如日中天时,一个称之为“Mamba”的架构横冲出世,在语言建模上与Transformers不相上下,具有线性复杂度,同时具有5倍的推理...

Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集...

近年来,视觉Transformer及其各种形式在人体姿态估计中具有重要意义。通过将图像块视为Token,Transformer可以明智地捕获全局关系,通过...

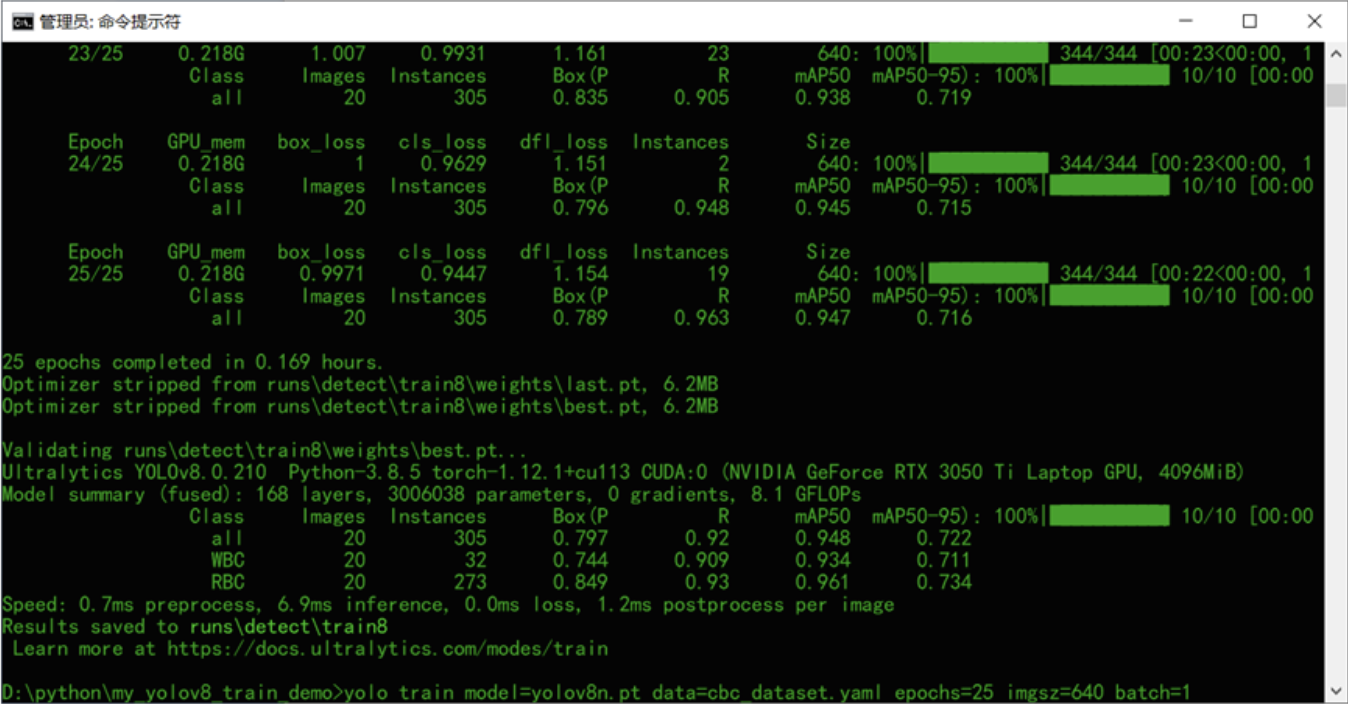
数据集包含 360 张红血细胞图像及其注释文件,分为训练集与验证集。训练文件夹包含 300 张带有注释的图像。测试和验证文件夹都包含 60 ...
12 月 27 日,中国市占第一的消费级 AR 品牌雷鸟创新发布大模型语音助手 Rayneo AI(beta 版),并通过雷鸟 X2 消费级真 AR 眼镜内测上线。

人脸盲复原是计算机视觉领域的一个重要课题,由于其广泛的应用而受到人们的广泛关注。在这项工作中,我们深入研究了利用预训练的稳定扩...

最近,Segment Anything Model (SAM) 已经展示出了强大的分割能力,在计算机视觉领域引起了广泛关注。基于预训练的 SAM 的大量研究工作...

自动驾驶车辆(AVs)必须准确检测来自常见和罕见类别的物体,以确保安全导航,这催生了长尾3D目标检测(LT3D)的问题。当代基于激光雷达...



 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西