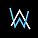动态场景去模糊(相机抖动、目标运动导致的模糊)是底层视觉中一种极具挑战性的任务。不同于已有方法中的参数独立或参数共享模式,作者提...
这篇文章介绍了为生产系统构建机器学习过程的很多方面的内容,都是从实践中总结出来的。作者:Marifel编译:ronghuaiyang首发:AI公园公...

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美...

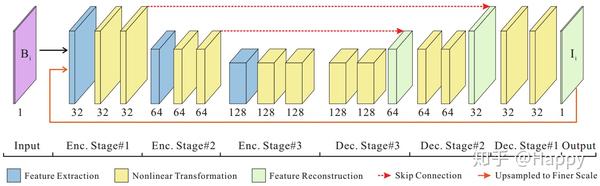
DeblurGANv2是乌克兰天主教大学的Orest Kupyn等人提出的一种基于GAN方法进行盲运动模糊移除的方法。它在第一版DeblurGAN基础上进行改进...
DeblurGAN是乌克兰天主教大学的Orest Kupyn等人提出的一种基于GAN方法进行盲运动模糊移除的方法。受启发于SRGAN与CGAN的成功,将图像模...

该文是原SID团队(UIUC+HKUST+Intel)在SID基础上提出的一种适用于暗光视频的方法。深度学习已在极限低光成像领域取得了难以置信的效果。...

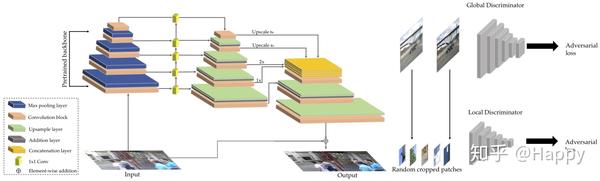
本文作者关注DCNN在图像去噪领域所取得的极大的关注。然而,不同类型的深度学习方法在处理不同类型噪声时表现差异较大,比如基于判别学...
当下,按地区划分,全球半导体业主要有六大板块,分别是美国、欧洲、日本、韩国、中国台湾和中国大陆。在2019年,受到多种因素的影响,...
芯片企业的投资项目,在单纯财务收益之外,大家会比较自然地联想到特殊产品/功能定制、供应链议价权甚至供应链安全等相关因素。今天,我...
华为诺亚方舟实验室的论文《Co-Evolutionary Compression for Unpaired Image Translation》被ICCV 2019录用,该论文首次提出针对GAN中...
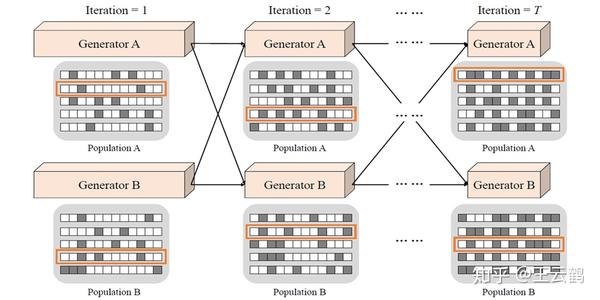
这篇文章是自己在上大数据分析课程时老师推荐的一篇文章,当时自己听着也是对原作者当年的的思路新奇非常敬佩,相信很多伙...
论文题目:SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards
【论文阅读】Mastering Complex Control in MOBA Games with Deep Reinforcement Learning

在开始说基于Stochastic Policy的方法之前,我们需要了解一下Policy Gradient的方法。在Policy Gradient里面有一个非常重要...

在强化学习中的值函数近似算法文章中有说怎么用参数方程去近似state value ,那policy能不能被parametrize呢?其实policy可...

在开始说值函数近似方法之前,我们先回顾一下强化学习算法。强化学习算法主要有两大类Model-based 的方法和Model-free 的方...

在上一篇文章强化学习中的无模型预测中,有说过这个无模型强化学习的预测问题,通过TD、n-step TD或者MC的方法能够获得值函...

在大多是强化学习(reinforcement learning RL)问题中,环境的model都是未知的,也就无法直接做动态规划。一种方法是去学MDP...

上一节我们说了马尔可夫决策过程,它是对完全可观测的环境进行描述的,也就是观测到的内容完整决定了决策所需要的特征。马...
上节聊完了这个强化学习从直观上的一些理解。以及它和其他的机器学习方法的一些异同点。这一节来唠唠强化学习中的一些基本...