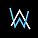本文作者来自于宾夕法尼亚州立大学,总结了《十个关键点》,强化学习和最优控制的81页PPT汇总。来源:book.yunzhan365报道:深度强化学...
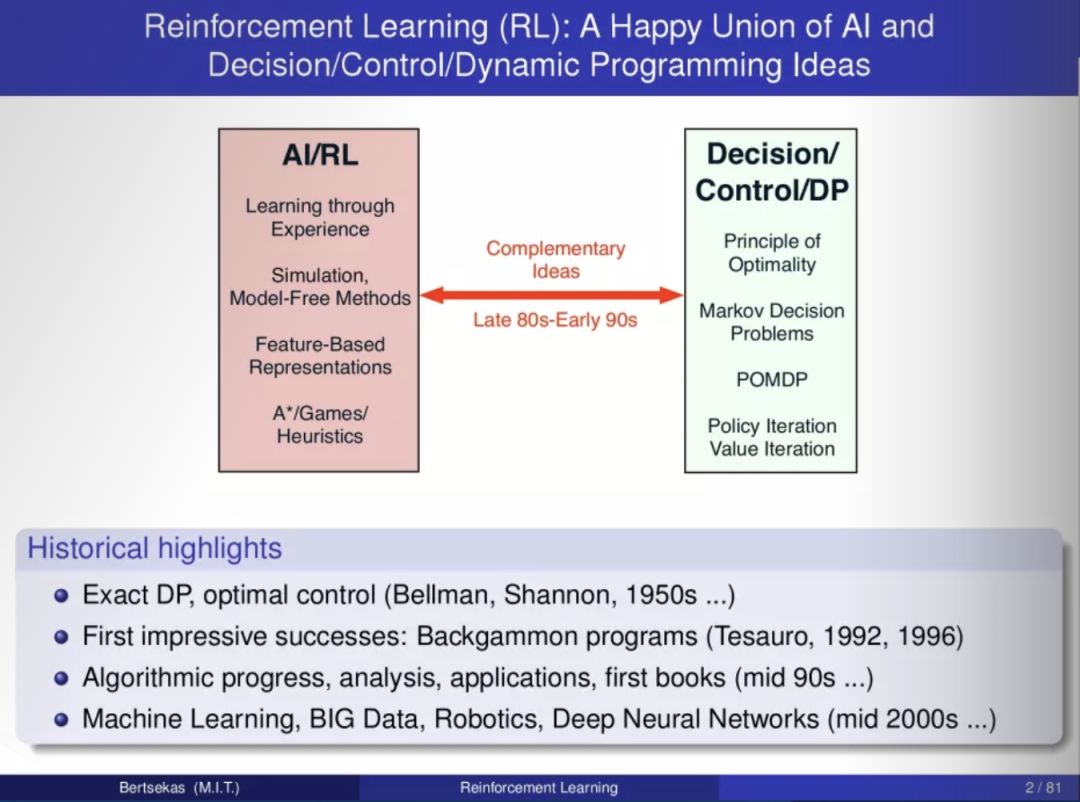
本文作者关注DCNN在图像去噪领域所取得的极大的关注。然而,不同类型的深度学习方法在处理不同类型噪声时表现差异较大,比如基于判别学...
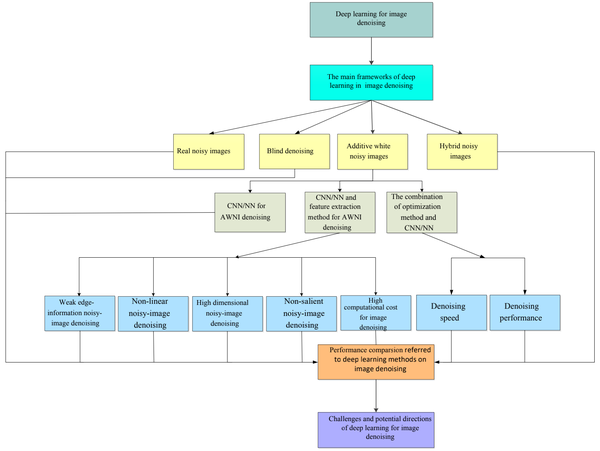
本文提出了一种基于感兴趣区域(RoI)的机器人抓取检测算法,以同时检测目标及其在物体重叠场景中的抓取。作者: 康斯坦奇首发:3D视觉...
ARM Cortex-A 系列的Cortex-A77的 ARM 文档集TARM Cortex-A 系列是一系列用于复杂操作系统和用户应用程序的应用程序处理器。Cortex-A 系...
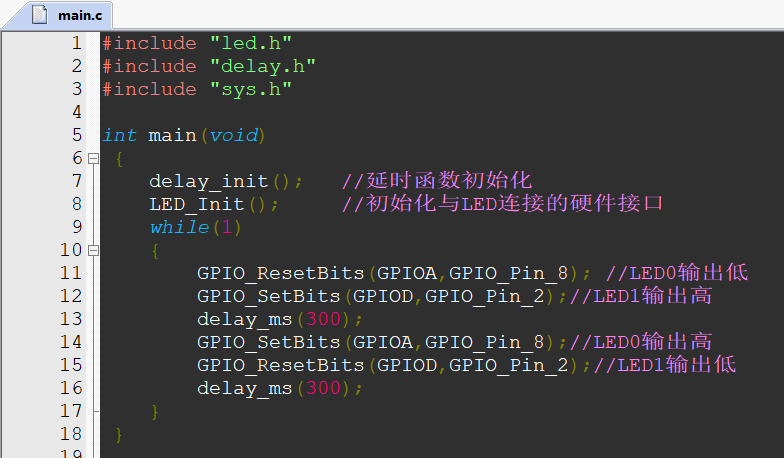
学习系统时钟之前先问大家一个问题?这是一个跑马灯的程序,为什么我们没有在主函数中配置系统时钟,却可以正常的执行流水灯代码呢?我想...
世界正在快速进入万物互联的IoT时代,智能手机、智慧家庭、智能网联汽车、智慧城市、工业物联网、可穿戴设备等已成为公众耳熟能详的词汇...
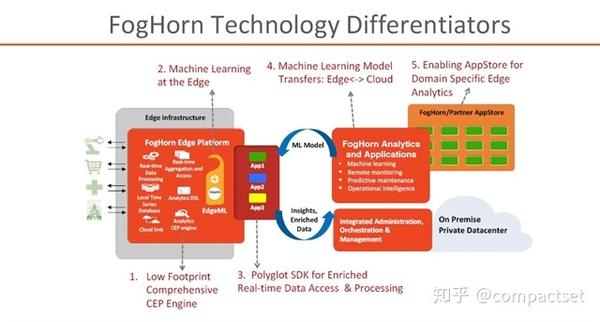
1. FogHornFogHorn是真正的在边缘侧进行机器学习计算的物联网边缘计算软件。这句话有点绕口,但是为了强调没法子——谁让好多厂商都在吹自...
人工智能(AI)的到来创造了许多机会,从更好的顾客产品消费体验到工厂车间的自动化质量监控,有关AI用例正呈指数增长。创新的信号处理...

当下,按地区划分,全球半导体业主要有六大板块,分别是美国、欧洲、日本、韩国、中国台湾和中国大陆。在2019年,受到多种因素的影响,...
芯片企业的投资项目,在单纯财务收益之外,大家会比较自然地联想到特殊产品/功能定制、供应链议价权甚至供应链安全等相关因素。今天,我...
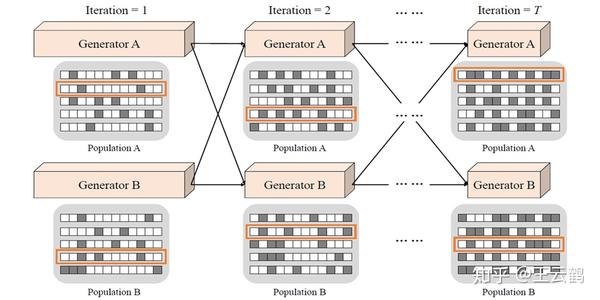
华为诺亚方舟实验室的论文《Co-Evolutionary Compression for Unpaired Image Translation》被ICCV 2019录用,该论文首次提出针对GAN中...
这篇文章是自己在上大数据分析课程时老师推荐的一篇文章,当时自己听着也是对原作者当年的的思路新奇非常敬佩,相信很多伙...
将其扩展到MCTS上,得到了 Maximum Entropy for Tree Search (MENTS)算法。
论文题目:SQIL: Imitation Learning via Reinforcement Learning with Sparse Rewards
论文题目:Reinforcement Learning with Deep Energy-Based Policies

【论文阅读】Mastering Complex Control in MOBA Games with Deep Reinforcement Learning

在开始说基于Stochastic Policy的方法之前,我们需要了解一下Policy Gradient的方法。在Policy Gradient里面有一个非常重要...

在强化学习中的值函数近似算法文章中有说怎么用参数方程去近似state value ,那policy能不能被parametrize呢?其实policy可...

在开始说值函数近似方法之前,我们先回顾一下强化学习算法。强化学习算法主要有两大类Model-based 的方法和Model-free 的方...

在上一篇文章强化学习中的无模型预测中,有说过这个无模型强化学习的预测问题,通过TD、n-step TD或者MC的方法能够获得值函...

在大多是强化学习(reinforcement learning RL)问题中,环境的model都是未知的,也就无法直接做动态规划。一种方法是去学MDP...

上一节我们说了马尔可夫决策过程,它是对完全可观测的环境进行描述的,也就是观测到的内容完整决定了决策所需要的特征。马...
马尔可夫决策过程 (Markov Decision Process,MDP)是序贯决策(sequential decision)的数学模型,一般用于具备马尔可夫性的...
上节聊完了这个强化学习从直观上的一些理解。以及它和其他的机器学习方法的一些异同点。这一节来唠唠强化学习中的一些基本...
在19年4月,有写过一篇强化学习的入门直观简介。强化学习通俗入门简介(一)。感兴趣的可以看一下,如果知道一些基本概念的话...
本文将之前的一篇基于强化学习的倒立摆控制策略Matlab实现文章再次进行了扩充。
什么是强化学习(Reinforcement Learning)?他和监督学习有什么区别?这里我将从监督学习切入,来用几篇文章解释清楚强化学...

论文题目:Addressing Function Approximation Error in Actor-Critic Methods

论文题目:Continuous Control With Deep Reinforcement Learning

stochastic policy的方法由于含有部分随机,所以效率不高,方差大,采用deterministic policy方法比stochastic policy的采...


 安谋科技自研产品
安谋科技自研产品
 AI 应用
AI 应用
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西