非常荣幸能够获得SiRider S1芯擎工业开发板测评机会。SiRider S1 是 Radxa 与芯擎科技及安谋科技联合推出工业单板计算机,融合芯擎科技...

Claude3.5sonnet简单介绍:Claude 3.5 Sonnet是Anthropic公司开发的先进人工智能语言模型,是Claude系列的最新版本之一。它具有强大的自...
RAG+Agent人工智能平台:RAGflow实现GraphRA知识库问答,打造极致多模态问答与AI编排流体验1.RAGflow简介最近更新:2024-09-13 增加知识...

大模型分布式训练往往需要上千乃至上万 GPU 卡进行超大规模并行训练,是典型的计算密集型和通信密集型场景。

在科技浪潮是推动下,传统农业正经历一场智能化变革。作为现代农业的「千里眼」,农业遥感通过收集卫星和无人机等平台的遥感数据,被广...

关于vLLM,之前介绍过vLLM框架(vLLM源码之框架执行)和PagedAttention的算子(vLLM源码之PagedAttention),本文主要结合代码,希望可...

标题取自 LLamaIndex,这个内容最早提出于今年 2 月份 LlamaIndex 官方博客。从 22 年 chatGpt 爆火,23 年大模型尝鲜,到 24 年真正用 ...

检索增强生成(RAG)是一种新兴的 AI 技术栈,通过为大型语言模型(LLM)提供额外的 “最新知识” 来增强其能力。

原文:[链接]本文主要介绍vLLM推理引擎的框架执行流程 (v0.1.2),相关文章:vLLM源码之PagedAttention(持续更新)引用本文内容主要源于...

通过指尖操作,在“智能小虹”平台中输入关键词“居住证补办”,几乎同时,详尽的办理流程便清晰展现;通过整合居民办事相关政策库、基层治...
为了引出什么是 RAG,先看一下 LLM 当前存在的问题:幻觉、过时的知识、不透明无法追踪的推理过程
地瓜机器人新一代机器人开发者套件RDK X5,搭载旭日5智能计算方案,极简机器人开发体验,助力机器人开发一步通关(更多产品信息请关注20...

近期,一款叫《黑神话:悟空》的国产游戏突然在全网“刷屏”了,作为中国首个真正意义上的国产3A游戏大作,《黑神话:悟空》自全球发售以...
该项目整合了编程、AI、产品设计、商业科技及个人成长等多领域的精华内容,源自顶尖技术企业和社群。借助先进语言模型技术,对精选文章...
经历9年成长,地瓜机器人今天全新亮相!作为业界唯一面向机器人打造软硬件底座的企业,地瓜机器人将承载着「成为机器人时代的Wintel」的...

SearXNG 是一个免费的互联网元搜索引擎,整合了各种搜索服务的结果。用户不会被跟踪,也不会被分析。
无缝融入,即刻智能[二]:Dify-LLM平台(聊天智能助手、AI工作流)快速使用指南,42K+星标见证专属智能方案1.快速创建应用你可以通过 3 种...
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入...

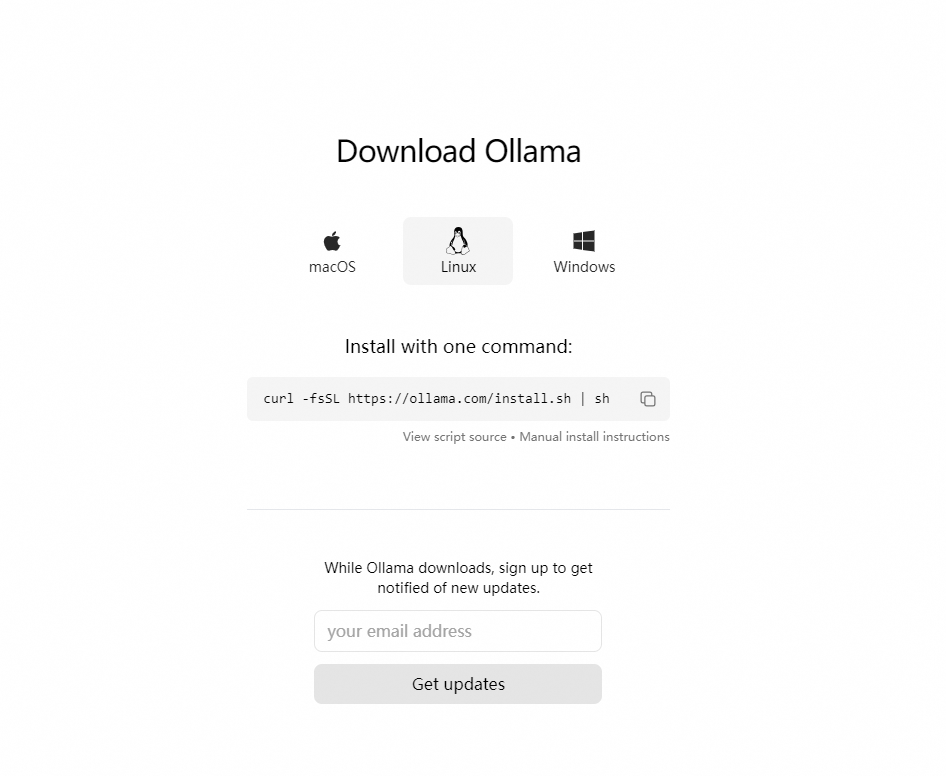
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。,这是 Ollama 的官网地址:[链接]
本文主要介绍vLLM推理引擎的PagedAttention算子实现,关于PagedAttention内容,后续会持续更新。

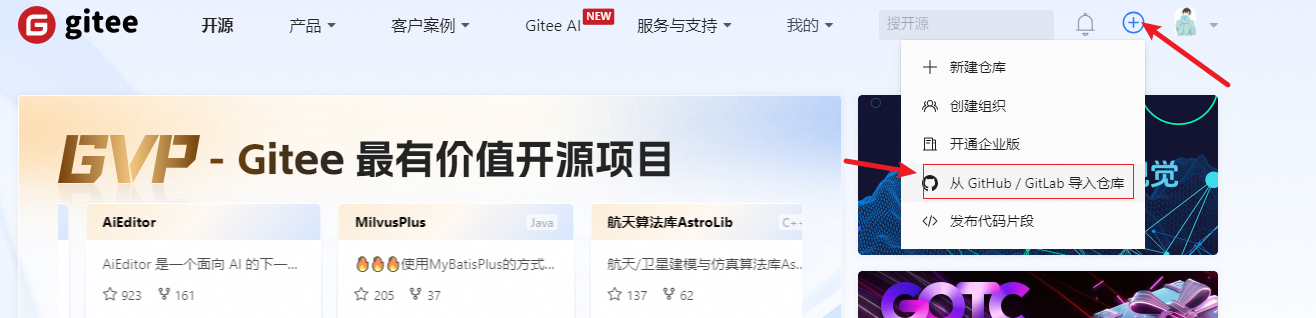
本文介绍了五种加速在国内访问和下载 GitHub 的方法,包括:使用 Gitee 平台加速克隆代码、修改 hosts 文件、使用油猴脚本、通过在线镜...
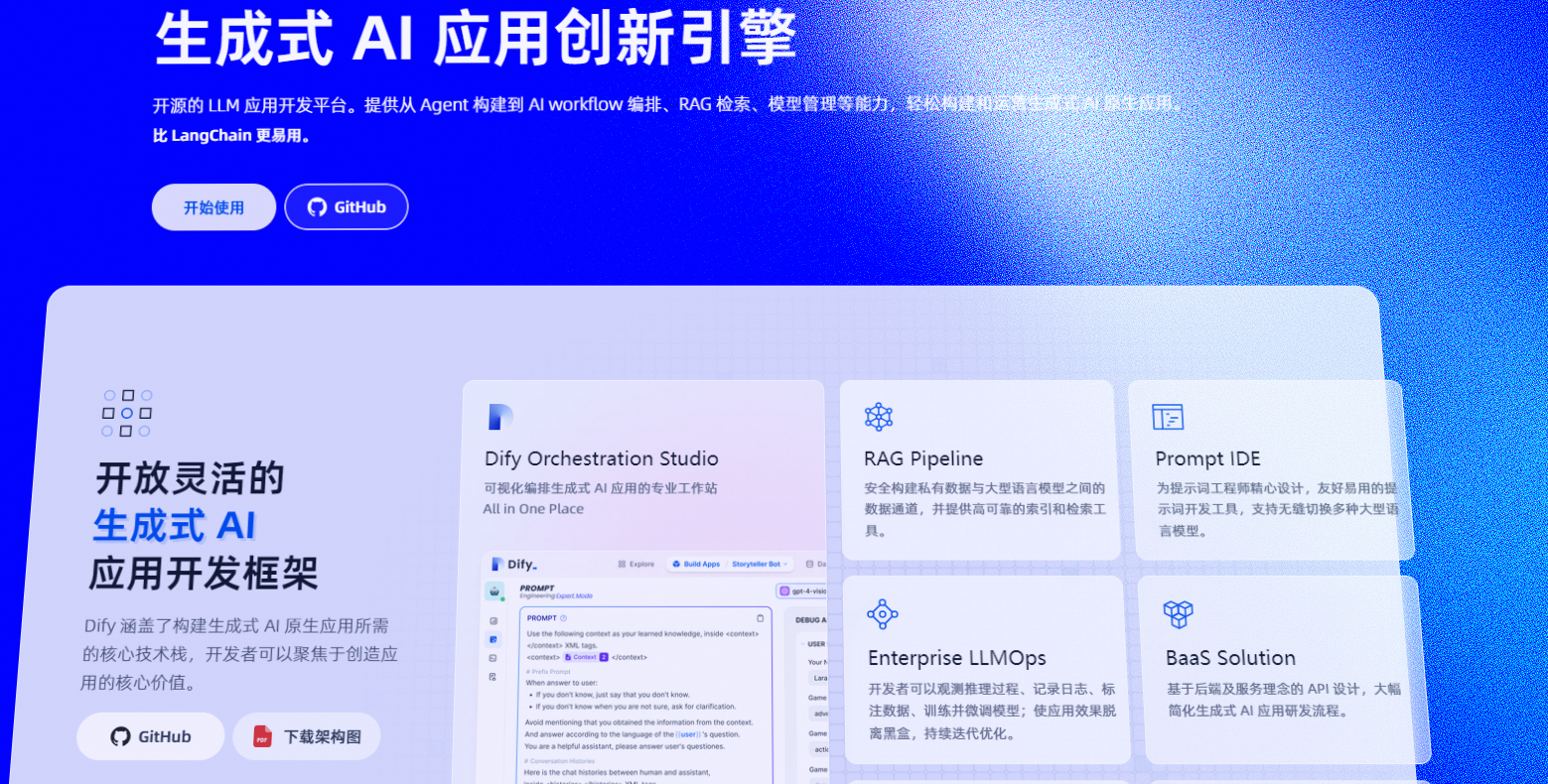
Dify,一款引领未来的开源大语言模型(LLM)应用开发平台,革新性地融合了后端即服务(Backend as a Service,BaaS)与LLMOps的精髓,为开...
感谢 @顾子韵 ,Tass及其他朋友的帮助,缺少他们的帮助无法完成该教程。感兴趣的朋友私聊我或他进群一起学习。

从精准的天气预测到未来的元宇宙生活畅想,全社会的数字化进程都离不开算力的支持。人们对未来算力的描述是会像水厂、电厂提供水电一样...

创建 TPU以下步骤展示了如何创建用于您的模型的 TPU 虚拟机。创建环境变量: {代码...} 环境变量说明 {代码...} 在您的活跃 Google Clou...

随着巴黎奥运会开幕式为全世界掀起一场文艺浪潮,塞纳河畔也从浪漫艺术的盛宴,转向体育竞技的击攘。让全世界不可错过巴黎前方的每刻高...

糖尿病是全球上升最快的主要慢性病,可造成失明、肾功能衰竭、截肢、脑卒中、心肌梗死等,亦与肿瘤感染等密切相关。其中,糖尿病视网膜...

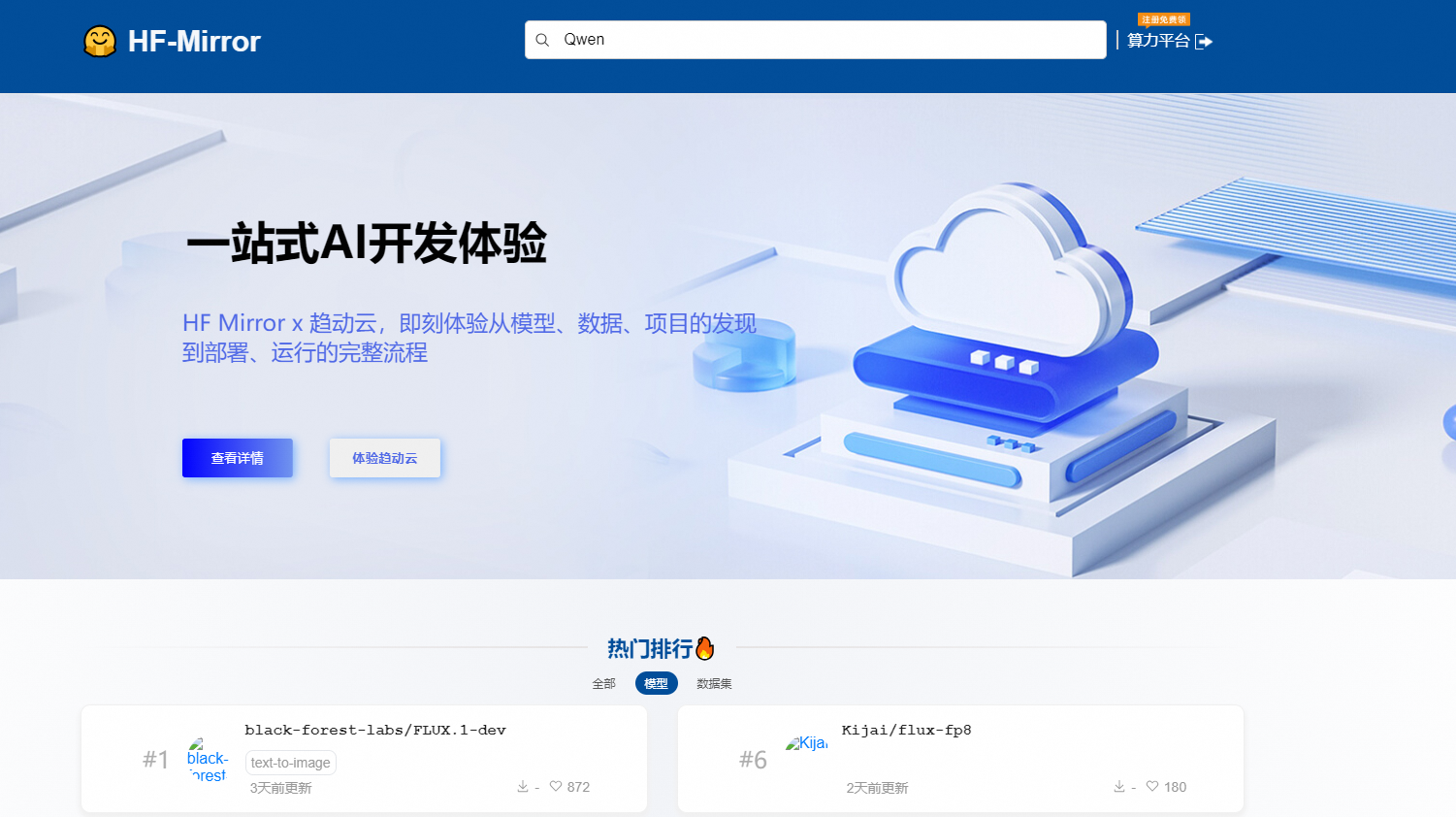
告别Hugging Face模型下载难题:掌握高效下载策略,畅享无缝开发体验Huggingface国内开源镜像:[链接] 里面总结了很多下载的方法,下面...
在无线通信中,信号经由无线信道传递通常会受到能量衰减、噪声干扰等影响,导致用户侧接收到的信号与基站发出的信号存在一定程度的变化...

北京时间7月30日清晨,英伟达创始人兼CEO黄仁勋与Meta创始人兼CEO马克·扎克伯格,在美国丹佛举行的第50届SIGGRAPH图形大会上完成了一场6...


 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西
















