IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,...

科幻小说作家 Vernor Vinge 曾经说过,人类最后一项伟大的发明将是第一台可以自我复制的机器,而谷歌 AutoML 团队的科学家们就正在做类...

作者:Barış KaramanFollow编译:ronghuaiyang 首发:AI公园公众号今天给大家介绍客户分群方面的内容,为什么要对客户进行细分,如何细...

后处理(Post-Processing),在图形学和游戏开发等领域是提升最终画面呈现品质的重要渲染技术。后处理渲染技术的好坏,往往决定了游戏画...

疫情发生以来,湖北的情况牵动着所有人的心绪。我们见证了封城带来的困难,致敬了援鄂医护人员的伟大,雀跃于武汉重启的壮丽。随着湖北...

宅了这么久,在家钻研厨艺了这么久,你现在最想吃什么?对这个问题进行投票,火锅毫无争议将碾压式夺冠。这个世界就是如此,生活不能只...

【嘉德点评】上海芯元基科技半导体公司提出的GaN基复合衬底技术,结合企业自身的LED芯片技术,在大大提高LED出光效率的同时,还能大幅降...
作者:Barış KaramanFollow编译:ronghuaiyang 首发:AI公园公众号这一系列的文章通过了一个实际的案例,向大家介绍了如何使用机器学习...

旷视研究院联合电子科大、苏黎世理工共同提出DeepLiDAR模型,它可从一张彩色图像和一个稀疏深度生成室外场景之下的精确的稠密深度。
来源:腾讯技术工程微信号回顾一下自己参与的智能客服系统项目,从技术调研到游戏领域的对话文本数据分析和任务细分定义,再到建模调优...

人脸姿态估计算法,主要用以估计输入人脸块的三维欧拉角。一般选取的参考系为相机坐标系,即选择相机作为坐标原点。姿态估计可用于许多...

大多数时候,人们使用不同的深度学习框架和标准开发工具箱。(SDKs),用于实施深度学习方法,具体如下:
近期最火的游戏,恐怕要数任天堂的年度最佳理财单品——《动物森友会》。但一些没有掌机的朋友,只能留着柠檬的泪水,看别人在岛上大联欢。

AI 技术的发展和大数据时代的到来令知识图谱的自动化构建成为可能,尽管现阶段还面临着一些挑战,但已有不少企业在积极探索和尝试自动化...
强强联合,OPEN AI LAB 边缘AI推理框架Tengine加入ONNX联盟[链接]

论文题目:Imagination-Augmented Agents for Deep Reinforcement Learning

论文题目:Learning Predictive Models From Observation and Interaction

论文题目:model-ensemble trust-region policy optimization

论文题目:Model-Based Reinforcement Learning via Meta-Policy Optimization

论文题目:Recurrent World Models Facilitate Policy Evolution

model-free的强化学习算法已经在Atari游戏上取得了巨大成功,但是与人类选手相比,model-free的强化学习算法需要的交互数据...
过去一段时间,由于全球大部分公司开启远程办公,Zoom 这类工具的使用人数疯狂上升,从视频会议到朋友聚会都可以通过 Zoom 来实现,这也...

两年一度的国际计算机视觉大会 ICCV 2019 ( IEEE International Conference on Computer Vision) 将于当地时间 10 月 27 至 11 月 2 日...
导语:多轮对话聊天机器人,作为人工智能的典型应用场景,也是一项极具挑战的任务,不仅涉及多方面异构知识的表示、抽取、推理和应用,...

以「声音校准」而出名的瑞典音频技术解决方案商 Dirac,虽然在大众人群中鲜为人知,但它所属的音频技术已运用在包括哈曼卡顿、先锋、小...

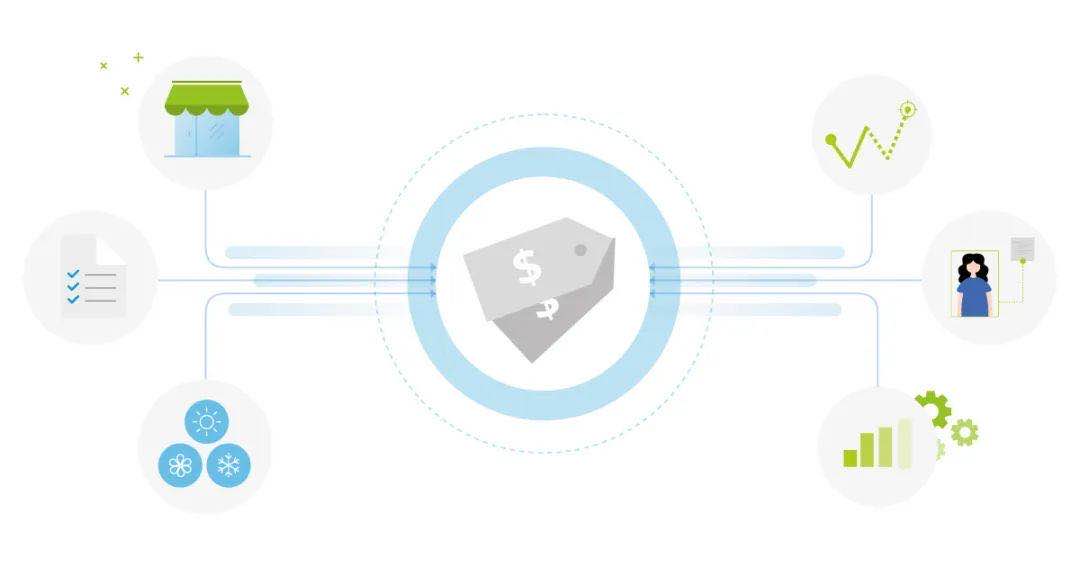
为商品或服务定价是经济学理论中的一个老问题。对于不同的目标,有大量的定价策略。一家公司可能会寻求最大化每一个单销售或整体市场份...
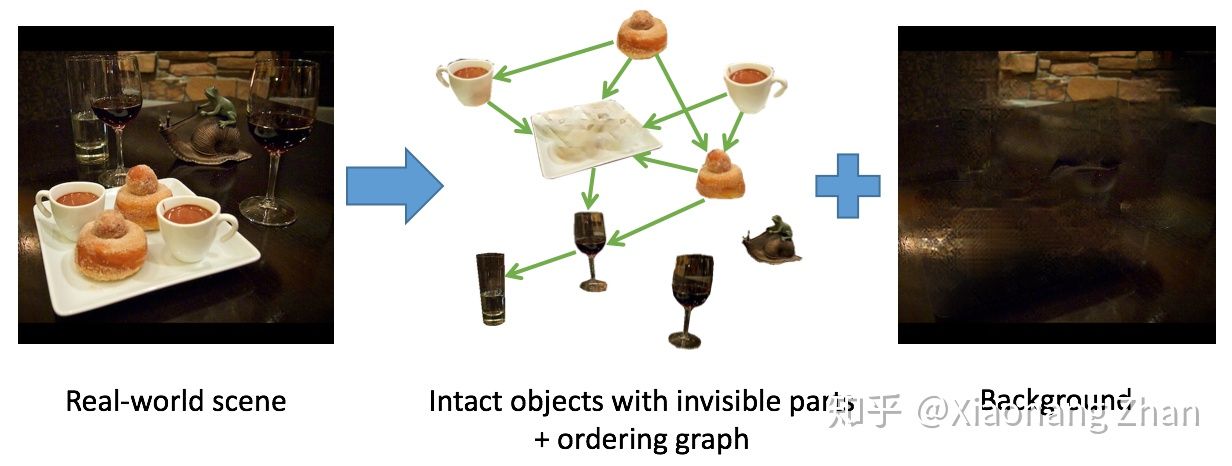
无监督的去遮挡和场景分解这个问题从18年底就开始思考了,因为并没有之前的工作很好地定义场景去遮挡这个问题,更别说解决,更别说用无...
集微网消息 由于新冠肺炎疫情导致线下活动暂时无法正常举办,集微网于2月初正式上线了“集微直播间”频道,以更专业、更多元化的形式为企...
如果抛开技术成熟度和可行性,大概每个人都可以描绘出一幅极具未来感的智能座舱的景象。比如,在完全无人驾驶的座舱中,人们可以完全自...

在5G、AI、工业互联网、IoT等所代表的一系列信息技术中,5G网络建设无疑是数字经济发展与产业迭代升级的基石,也引发了全社会的关注。



 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西



















