导读:本期19条。「新闻」部分三个最近开源的框架:清华大学计算机图形学组的Jittor、旷视动态图和静态图合一且训练推理一体的MegEngine...

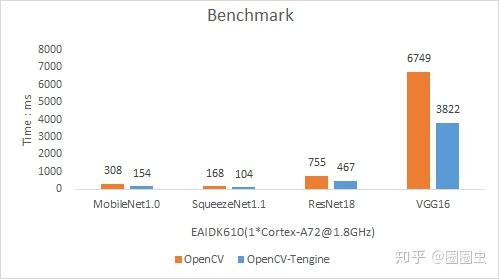
OpenCV版本迭代时,Tengine作为Arm平台的Backend加入OpenCV DNN Module,提升了OpenCV DNN在Arm平台的运行效率,加快深度学习神经网络的...
直播内容视频回放及PPT下载视频回放链接:[链接]PPT部分预览(文末提供下载)Q&A看了直播,大家可能对这块还有不少问题,大家可以去[链...

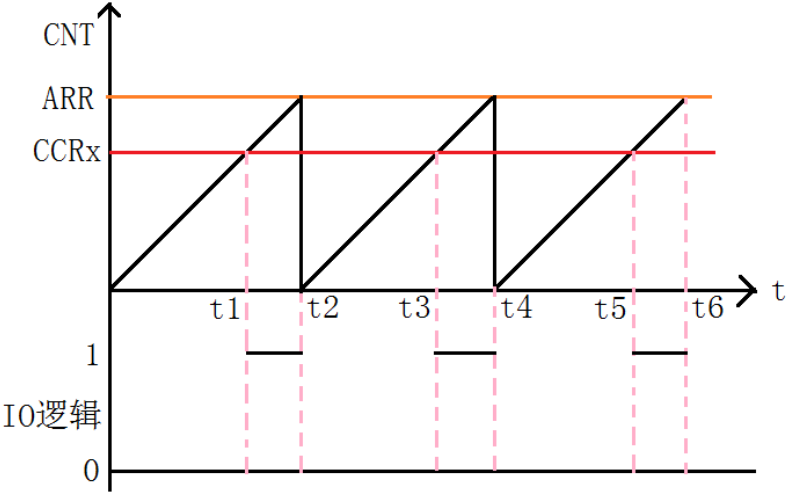
先说在开头啊,我们学习定时器总感觉它是很难的,这里我就不说他的编程难度,而是对于它的理解难度。学习定时器你就必须了解他的来龙去...
本周,华为2019年年报的发布,成为了科技界和社会各界关注的焦点。在特殊的时间背景,华为在2019年的整体表现当然格外引人注目。HMS生态...
视频回放及PPT下载视频回放链接:[链接]PPT部分预览(文末提供下载)Q&A看了直播,大家可能对这块还有不少问题,大家可以去[链接] 进行...

近日,国际知名调研机构 Gartner 发布 2020 年容器公有云竞争格局报告,阿里云再度成为国内唯一入选厂商。Gartner 报告显示,阿里云容器...

作者 | [张奇(司楚)]当线上碰到头疼的问题时,还在对着代码一行行的看?真的不太时髦了啊喂~俗话说的好 “问题排查不用愁,Arthas 来帮...

昨晚,苹果在 YouTube 上更新的支持视频中,不小心泄露了还未发布的电子追踪器 AirTag 的名称。

Arm中国创新教育中心(Arm Innovation Education Center China ,AIECC)是Arm中国和江北新区研创园共同打造,为南京江北新区打造集成电...
与传统应用程序相比,AR 应用程序需要更好的系统性能。人眼之所以可以轻松感知到物理世界的断断续续和缓慢的,是因为我们已经习惯了。但...

STM32 自2007年推出全世界第一颗基于ARM Cortex-M架构的MCU起,逐渐成为嵌入式工程师最喜爱的平台,并在2018年取得中国MCU市场占有率第...

之前我们有跟大家讨论过如何DIY一个轻型的Mobilenet SSD的物体检测器,本专栏的其他文章亦有介绍如何部署该类轻型MSSD的物体检测器于嵌...

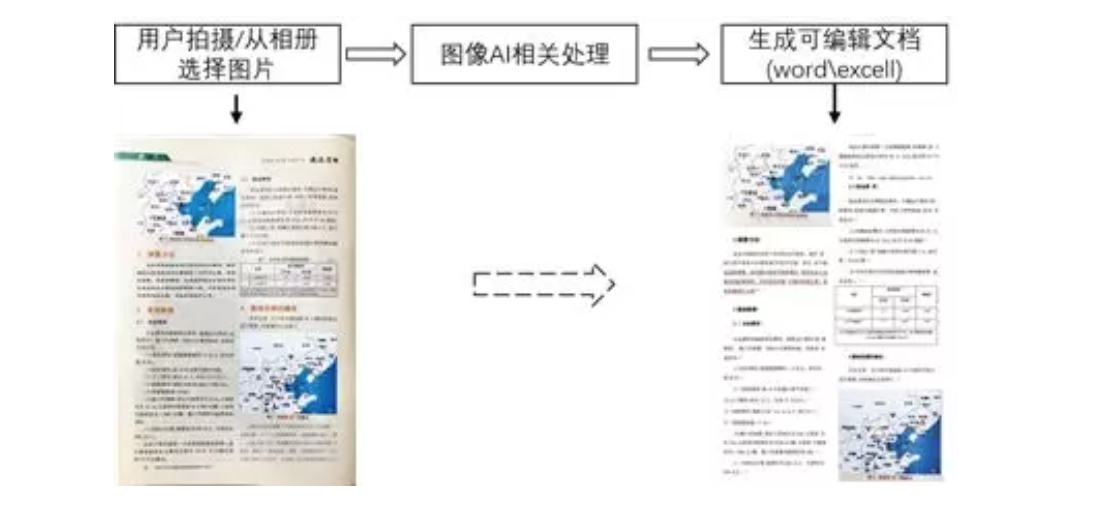
本文主要介绍基于深度学习的文档重建框架,通过文档校正、版面分析、字体识别和阅读排序将纸质文档智能转成可编辑的电子文档。相比较传...
在本节中,我将解释代码的结构。此外,还将给出实现CRF损失层的一个重要技巧。最后,会公布Chainer(2.0版)实现的源代码。
2017年三星将代工业务独立了出来,此后,三星曾多次强调要挑战代工领头羊台积电的地位。但根据相关调研机构所统计的2019年第四季度两者...
在过去的五年左右的时间里,已经有很多关于加速计算成为新常态以及关于通用处理器进入数据中心时代的讨论,这是有充分理由的。因为关于...
看了很多关于物联网的答案,我发现很多人对物联网的概念有很多误解。因此整理了一些误区。作者:与子同袍首发:物联网前沿技术观察
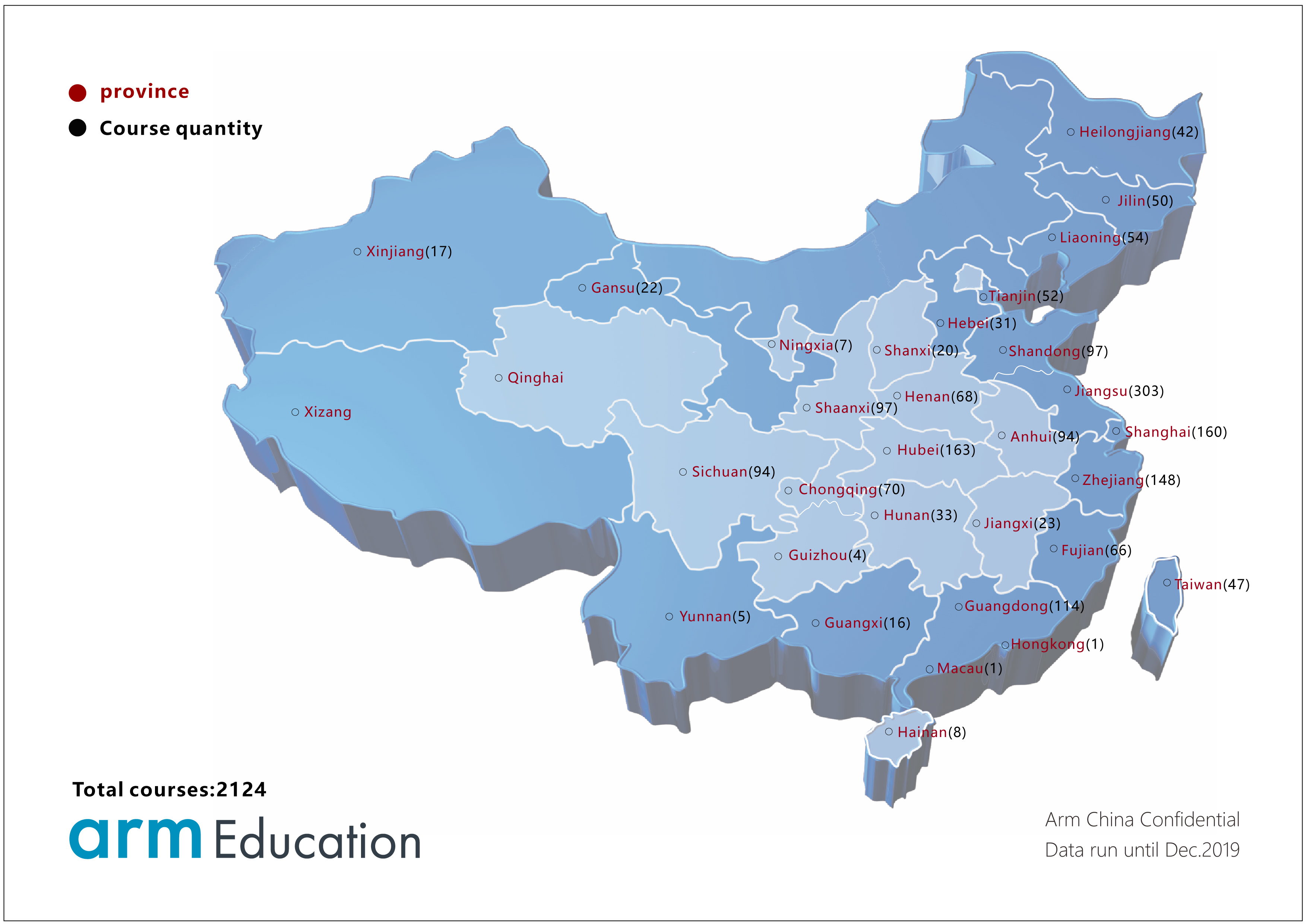
很多老师已经对Arm教育计划及教育套件非常熟悉并且应用在课堂教学中了,截止到2019年末,全国院校共有2124门课程使用了Arm教育套件。
本篇文章提供的是 Arm Allinea Studio 20.0 for RHEL 8.x 的1个文件。
IEEE 国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 将于 6 月 14-19 日在美...

Elasticsearch的聚合查询,跟数据库的聚合查询效果是一样的,我们可以将二者拿来对比学习,如求和、求平均值、求最大最小等等。
老人的新闻视频,大人的远程会议,孩子的在线课堂,全家的娱乐休闲……在与网络相濡以沫的时光里,想必这样的抱怨也时有发生:
近日,国际知名调研机构 Gartner 发布 2020 年容器公有云竞争格局报告,阿里云再度成为国内唯一入选厂商。Gartner 报告显示,阿里云容器...

BFF 全称是 Backends For Frontends (服务于前端的后端),起源于 2015 年 Sam Newman 一篇博客文章《Pattern: Backends For Frontends —...

函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传。函...

春天已经到来了,Arm Development Studio的最新更新也随之而来。 此2020.0版本在所有组件中添加了最新的Arm IP支持和有用的新功能。 此...

作为以手机为主要平台的移动社交应用,微信内大部分业务生成的数据是有共性可言的:数据键值带有时间戳信息,并且单用户数据随着时间在不...
由于CMSDK提供的是一个perl脚本,因此需要用到linux,当然也可以自己研究windows下的perl脚本如何执行。
Everspin宣布了其MRAM解决方案的几个新的应用程序和客户。首先是nvNITRO存储加速器产品系列。这些新卡(适用于要求苛刻的应用,例如金融...



 安谋科技自研产品
安谋科技自研产品
 AI 应用
AI 应用
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西

























