Neoverse S3 产品引入了我们的第三代基础设施专用系统 IP,是下一代基础设施 SOC 的理想基础,适用于从 HPC 和机器学习到边缘和 DPU 的...

LiRank是LinkedIn在2月份刚刚发布的论文,它结合了最先进的建模架构和优化技术,包括残差DCN、密集门控模块和Transformers。它引入了新...
作为人类赖以生存和发展的物质基础,生态环境对人类健康的影响是潜移默化的。近年来,除了力促医疗技术提升、着力完善社保体系等方面外...

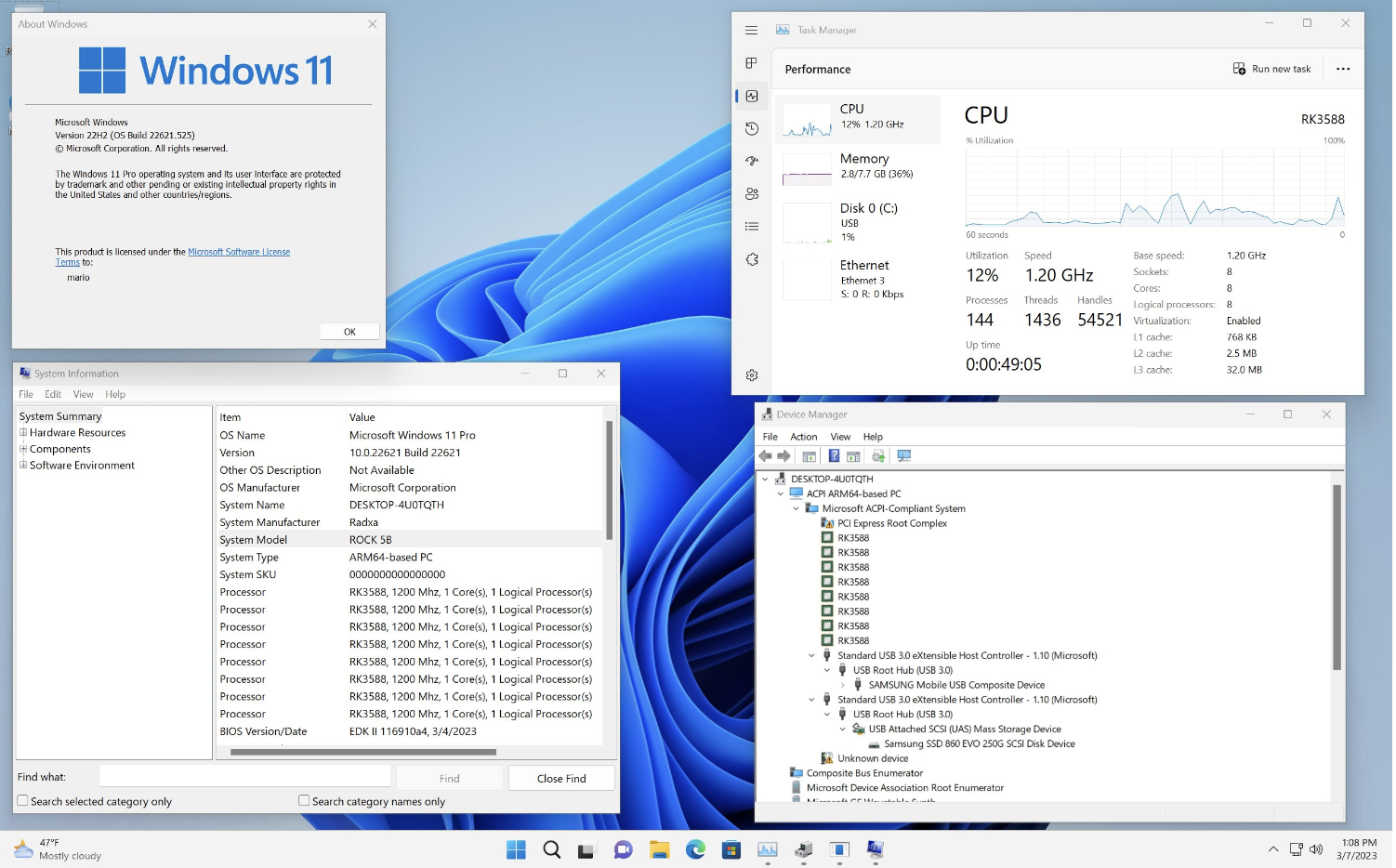
国外开发者 Mario Bălănică 在推特上发布了一张 ROCK 5B 成功运行 Windows 11 Arm 的截图,能正常联网。但由于缺乏驱动,GPU、PCIe 等部...
印刷电路板(PCB)是进行电子线路实验的基础。虽说现在通过万能的淘宝可以找到既便宜又快捷的制作电路板服务,但是对于一些实验性质的电...

我开始系统地看新能源汽车赛道是2021年,这个时间节点,其实已经没有新能源整车机会了,如果2015 2016年没有投新能源整车,那整车基本也...

ISP的功能可以简单概括为使后端能正确识别“真实的”世界。凸出真实和有用,这个有用主要是后端需要的信息;真实即使其更加接近现实中人眼...

在自动驾驶中,使用单目相机进行3D车道线检测对于各种下游规划和控制任务至关重要。最近的卷积神经网络(CNN)和Transformer方法通常在...

毫无疑问,数字化是当今社会发展最主要的主题之一,目前已有的千行百业都可以结合数字化升级重新做一遍,这就是产业升级。
进入2024年,AI大模型的应用全方位爆发。《幻兽帕鲁》的火爆,让行业看到了AI大模型带来的生产力变革。Sora的横空出世,让全世界惊呼虚...

进入2023年以来,ChatGPT的成功带动了国内大模型的快速发展,从通用大模型、垂直领域大模型到Agent智能体等多领域的发展。但是生成式大...
“万物互联”是最近几年听得最多的概念,在AI时代大模型涌现的洪流之下,借助先进的大模型工具,智能硬件变得更加智能,今天,让我们一起...
春节期间,OpenAI的最新技术成果——文生视频模型Sora惊艳登场,令海内外的AI从业者、投资人彻夜难眠。

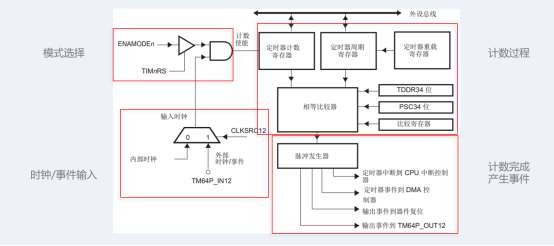
TMS320CC6748有4个定时器/计数器,均可配置为64位计数器、两个独立32位计数器及自动重装32位计数器,可以产生周期中断DMA事件及外部事件...
2023年是大语言模型和稳定扩散的一年,时间序列领域虽然没有那么大的成就,但是却有缓慢而稳定的进展。Neurips、ICML和AAAI等会议都有tr...
Minimum Pulse Width 最小脉冲宽度检查是为了确保时钟信号的脉冲宽度足够宽,使 cell 内部操作能够完成。也就是说,为了获得 cell 上稳...

眼睛方寸之间,疾病千差万别。去年底,由爱康集团与鹰瞳 Airdoc 联合发布的《四百万体检人群健康蓝皮书》显示,近年来眼底异常的总检出...

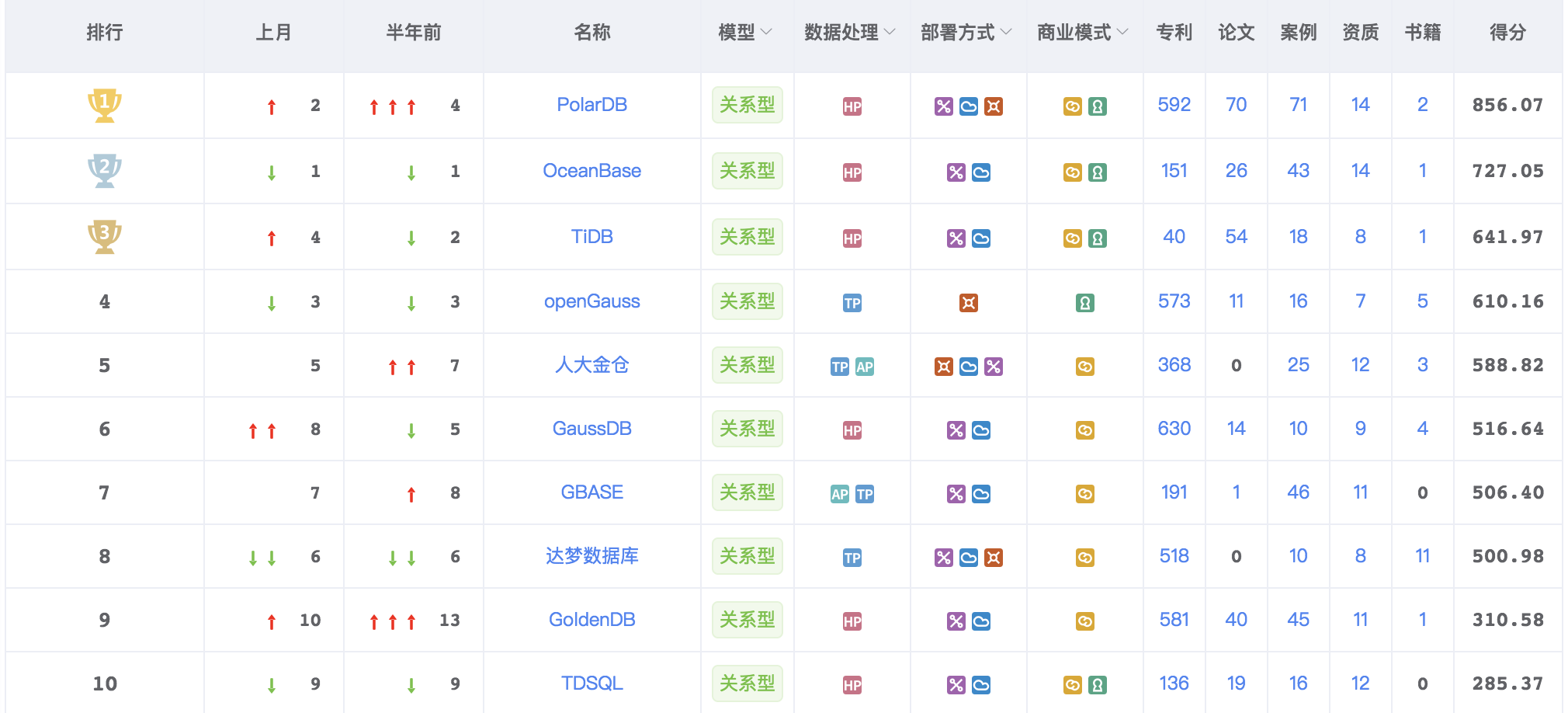
银装素裹覆大地,春意初醒待来临。2024年2月墨天轮中国数据库流行度榜单出炉,表现最亮眼的无疑是PolarDB,其自23年7月以来一路高歌猛进...
《数字信号处理》作为一门通信、电子、信息等本科专业基础课程,在《信号与系统》课程的基础上,学习离散信号与离散时间系统,尤其是离...

英伟达推出了自家版本的ChatGPT,名字很有GPU的味道——Chat With RTX。英伟达的这款AI聊天机器人和目前主流的“选手”有所不同。它并非是在...

这款产品中苹果深藏的众多技术奥秘。从芯片到显示屏,从传感器到电池,苹果在这个领域,出手就是王炸,多年来的技术创新和严谨布局。

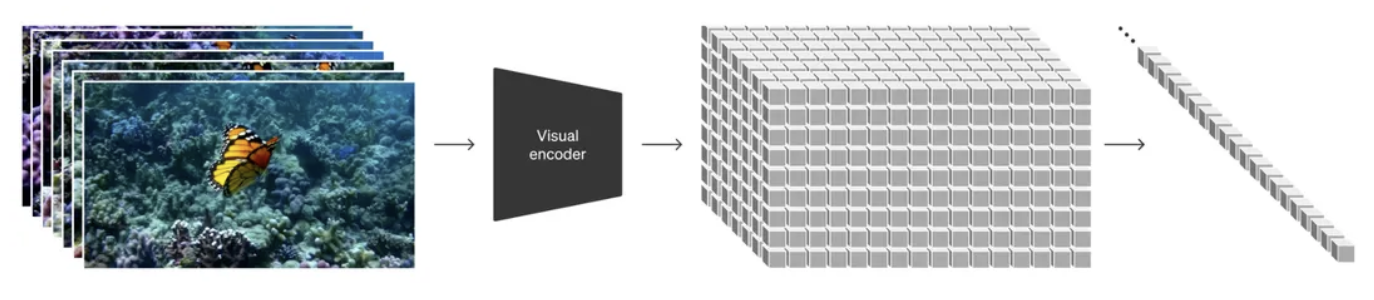
最近AI圈最火的无疑是OpenAI在2月15日发布的Sora。Sora可以根据文本生成一分钟的高清视频,生成的视频画质、连续性、光影等都令人叹为观...
新质生产力代表着一种生产力的跃迁,意思是“以科技创新发挥主导作用的生产力”。简单来说,就是新兴科技催生而来的颠覆性发展引擎。尤其...

玉兔辞旧岁,金龙启新程。甲辰龙年正月初二,以“龙兴九州 福聚四海”的主题,打造戏曲表达新样态,传递戏曲文化氛围的《2024年春节戏曲晚...

Sora文生视频模型深度剖析:全网独家指南,洞悉98%关键信息,纯干货Sora是一个以视频生成为核心的多能力模型,具备以下能力:文/图生成...

在 Arm,我们经常思考电子游戏。创造游戏有许多不同的目的--创造性、艺术性、技术性、教育性等等。所有情况下的共同点是,它们都是为了...

2023年是语言模型(llm)和图像生成技术激增的一年,但是视频生成受到的关注相对较少。今年刚到2月份,OpenAI就发布了一个惊人的视频生成...
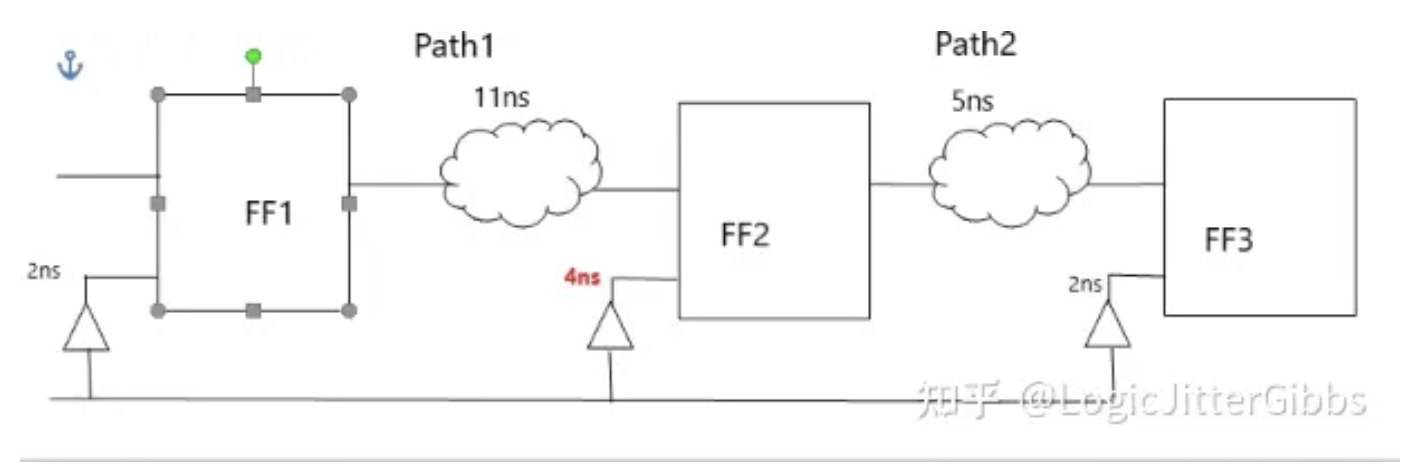
对于时钟树(clock tree)构建,传统的方法是采用零偏斜(Zero Skew)设计或者平衡偏斜(Balanced SKew)设计。即让每个时钟接收端(Sin...
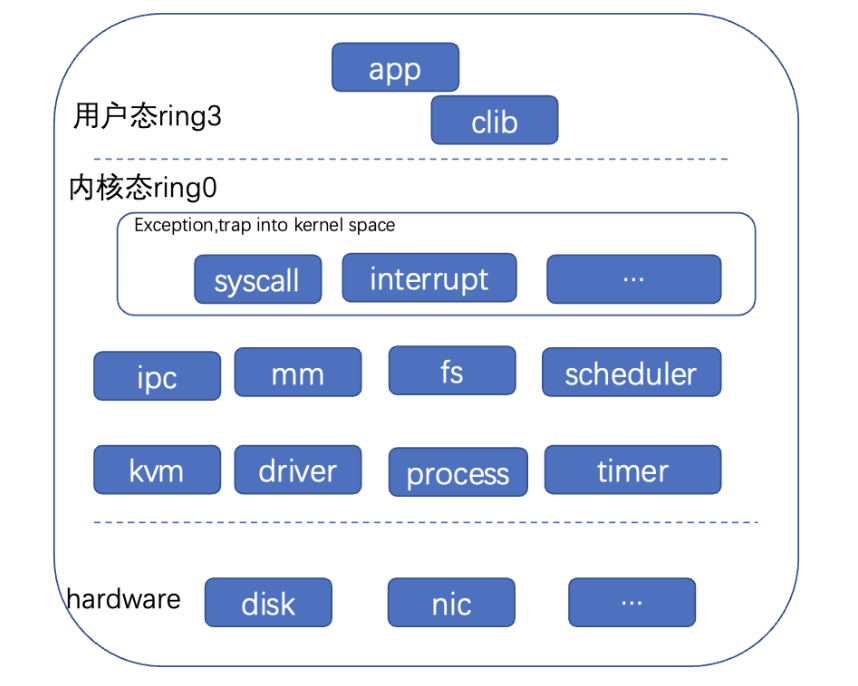
(1)内核、一些特权指令,例如填充页表、切换进程环境等,一般在ring0进行。内核态包括了异常向量表(syscall、中断等)、内存管理、调...
本文为墨天轮社区整理的2024年1月国产数据库大事件和重要产品发布消息。目录2024年1月国产数据库大事记 TOP102024年1月国产数据库大事记...



 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 AI 应用
AI 应用
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西























