第一次展开,从手机变成迷你平板;再一次展开,从平板变成笔记本屏幕。同时,其轻薄程度与直板机无异、搭载四千万像素镜头和新一代麒麟9...

随着《“十四五”数字经济规划》落地和“东数西算”工程推进,国内算力与存储建设迎来重大机遇。AI 与大模型的兴起,为数据中心带来新挑战与...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
科技行业的风云变幻,让巨头们的每一个动向都备受瞩目。近期,苹果对 Mistral AI 收购意向的传闻甚嚣尘上,而就在 9 月 9 日,荷兰光刻...

ABS-CBN是菲律宾最大的radio broadcaster、娱乐电视制作公司、节目联合发行提供商和媒体集团。它由阿尔托广播系统(ABS)和纪事广播网(...

摘要:智能算力产业的ESG表现正成为衡量其高质量发展的核心指标。环境维度上,“东数西算”工程通过设定PUE硬性目标推动绿色算力发展,2023...

毫无疑问,在数字经济时代,数据已成为继土地、劳动力、资本、技术之后的第五大生产要素。“得数据者得天下”不仅已成为全球共识,最大化...

8月下旬,《国务院关于深入实施人工智能+行动的意见》发布。文件中提到:到2027年,新一代智能终端、智能体等应用普及率需超过70%;到20...

近年来,大型语言模型 (LLM) 在医疗问诊中的应用越来越受到关注。在湖南省湘潭市雨湖区昭潭街道社区卫生服务中心,家庭医生刘彦博正根据...
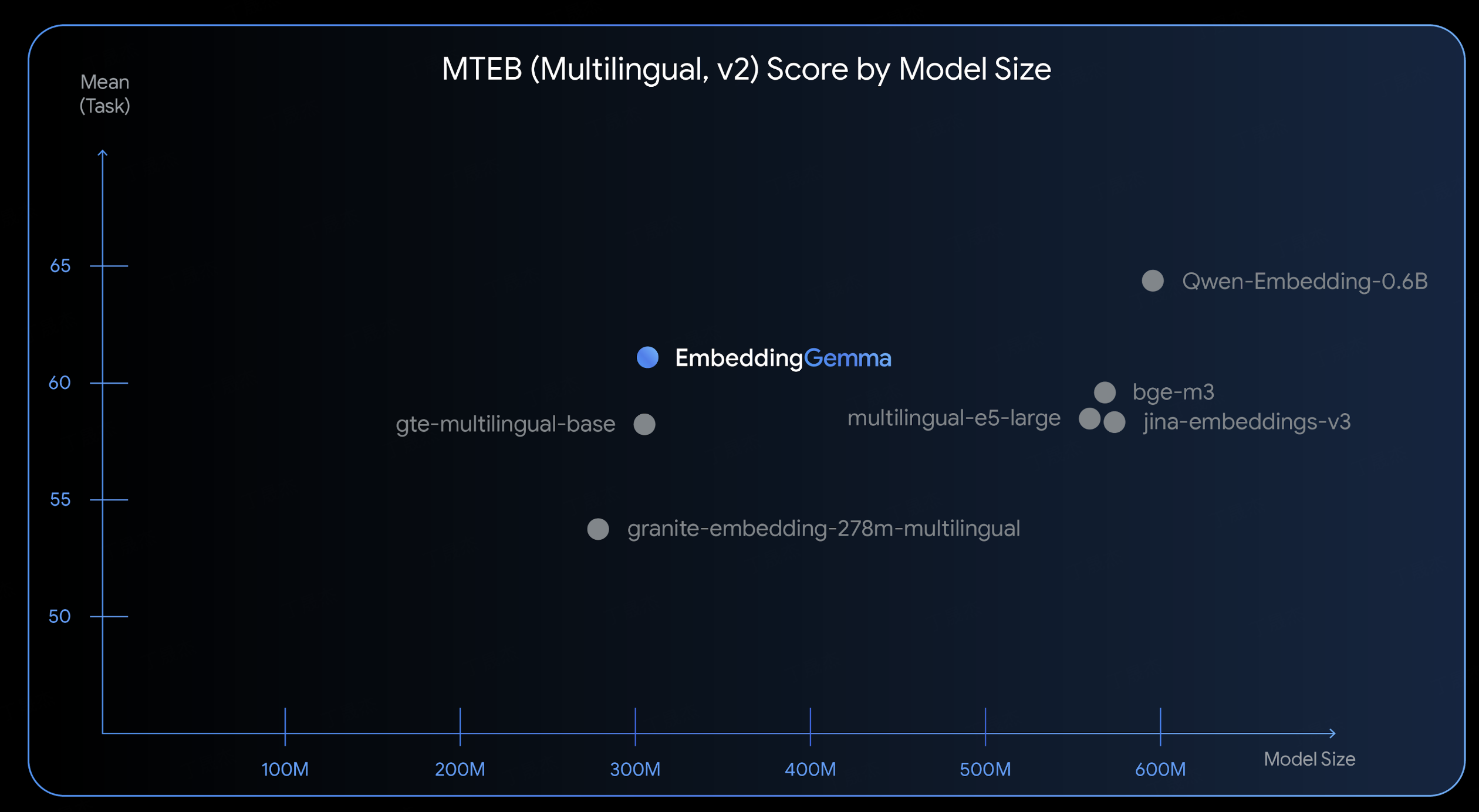
2025年9月,国际权威市场研究机构Omdia发布的《中国AI云市场,1H25》报告,让中国AI云市场的竞争格局清晰呈现:阿里云以35.8%的份额稳居...
曾几何时,我们对大模型的需求是“智能涌现”,是能够滔滔不绝为我们提供内容,什么问题都能给出令人眼花缭乱的回复。初见这种能力时的讶...

北京时间 9 月 10 日,苹果 2025 年秋季发布会再次引爆全球热议。然而,此次发布会的升级看点并不止于 iPhnoe 17 系列新机硬件配置升级...

“人如何表达自己的需求?互联网时代用文字,移动互联网时代用图片,等到人人都具备设计能力的那一天,3D设计会成为一种全新的需求表达形...

然而,在深海勘测任务中,面对海量且复杂的海洋数据,传统的计算方法显得力不从心,迫切需要高效数据处理与分析能力的支持。

2025年盛夏,钉钉在十周年发布会上,首款AI硬件DingTalk A1正式亮相。这款号称要重新定义智能办公的录音硬件,以其仅3.8毫米的超薄机身...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
细胞形态学是单细胞生物学领域的核心研究方向之一,其价值在于通过高通量图像分析技术,系统解析遗传扰动或药物扰动下细胞形态的动态变...
不久前,国务院正式印发了《关于深入实施“人工智能+”行动的意见》,首次系统性地提出人工智能与科技、产业、消费、民生、治理和全球合作...

《悟空传》里有一句话:“若天压我,劈开那天;若地拘我,踏碎那地。”道尽了孙悟空打破束缚的决心。今天的中国AI乃至各行各业,都无法忽...

去年开始,智能体成了科技圈最火的搞钱赛道。一批低代码、无代码开发平台,雨后春笋般冒了出来,把过去需要编程、调模型的复杂开发流程...

蛋白质是生命功能的执行者,其奥秘深藏于两个维度:一是由氨基酸首尾相连形成的一维(1D)序列,二是序列折叠缠绕形成的三维(3D)结构...

在 2025 CCF 全球高性能计算学术大会上,中国科学院大气物理研究所林鹏飞研究员团队报告了一项重要研究成果。该团队成功研发出耦合 Tran...

近几年,中国二手车市场出现一个奇特现象:一批行驶里程不足50公里的准新车以二手车身份低价流通。这些车辆大多贴着新能源标签,价格比4...

AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...

第一次展开,从手机变成迷你平板;再一次展开,从平板变成笔记本屏幕。同时,其轻薄程度与直板机无异、搭载四千万像素镜头和新一代麒麟9...
随着《“十四五”数字经济规划》落地和“东数西算”工程推进,国内算力与存储建设迎来重大机遇。AI 与大模型的兴起,为数据中心带来新挑战与...
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
科技行业的风云变幻,让巨头们的每一个动向都备受瞩目。近期,苹果对 Mistral AI 收购意向的传闻甚嚣尘上,而就在 9 月 9 日,荷兰光刻...
ABS-CBN是菲律宾最大的radio broadcaster、娱乐电视制作公司、节目联合发行提供商和媒体集团。它由阿尔托广播系统(ABS)和纪事广播网(...
摘要:智能算力产业的ESG表现正成为衡量其高质量发展的核心指标。环境维度上,“东数西算”工程通过设定PUE硬性目标推动绿色算力发展,2023...
毫无疑问,在数字经济时代,数据已成为继土地、劳动力、资本、技术之后的第五大生产要素。“得数据者得天下”不仅已成为全球共识,最大化...
8月下旬,《国务院关于深入实施人工智能+行动的意见》发布。文件中提到:到2027年,新一代智能终端、智能体等应用普及率需超过70%;到20...
近年来,大型语言模型 (LLM) 在医疗问诊中的应用越来越受到关注。在湖南省湘潭市雨湖区昭潭街道社区卫生服务中心,家庭医生刘彦博正根据...
2025年9月,国际权威市场研究机构Omdia发布的《中国AI云市场,1H25》报告,让中国AI云市场的竞争格局清晰呈现:阿里云以35.8%的份额稳居...
曾几何时,我们对大模型的需求是“智能涌现”,是能够滔滔不绝为我们提供内容,什么问题都能给出令人眼花缭乱的回复。初见这种能力时的讶...
北京时间 9 月 10 日,苹果 2025 年秋季发布会再次引爆全球热议。然而,此次发布会的升级看点并不止于 iPhnoe 17 系列新机硬件配置升级...
“人如何表达自己的需求?互联网时代用文字,移动互联网时代用图片,等到人人都具备设计能力的那一天,3D设计会成为一种全新的需求表达形...
然而,在深海勘测任务中,面对海量且复杂的海洋数据,传统的计算方法显得力不从心,迫切需要高效数据处理与分析能力的支持。
2025年盛夏,钉钉在十周年发布会上,首款AI硬件DingTalk A1正式亮相。这款号称要重新定义智能办公的录音硬件,以其仅3.8毫米的超薄机身...
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...
细胞形态学是单细胞生物学领域的核心研究方向之一,其价值在于通过高通量图像分析技术,系统解析遗传扰动或药物扰动下细胞形态的动态变...
不久前,国务院正式印发了《关于深入实施“人工智能+”行动的意见》,首次系统性地提出人工智能与科技、产业、消费、民生、治理和全球合作...
《悟空传》里有一句话:“若天压我,劈开那天;若地拘我,踏碎那地。”道尽了孙悟空打破束缚的决心。今天的中国AI乃至各行各业,都无法忽...
去年开始,智能体成了科技圈最火的搞钱赛道。一批低代码、无代码开发平台,雨后春笋般冒了出来,把过去需要编程、调模型的复杂开发流程...
蛋白质是生命功能的执行者,其奥秘深藏于两个维度:一是由氨基酸首尾相连形成的一维(1D)序列,二是序列折叠缠绕形成的三维(3D)结构...
在 2025 CCF 全球高性能计算学术大会上,中国科学院大气物理研究所林鹏飞研究员团队报告了一项重要研究成果。该团队成功研发出耦合 Tran...
近几年,中国二手车市场出现一个奇特现象:一批行驶里程不足50公里的准新车以二手车身份低价流通。这些车辆大多贴着新能源标签,价格比4...
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供...


 AI 应用
AI 应用
 安谋科技自研产品
安谋科技自研产品
 Arm 计算
Arm 计算
 SoC 芯片设计
SoC 芯片设计
 IoT 与嵌入式
IoT 与嵌入式
 教育与职场
教育与职场
 全球资源
全球资源
 SegmentFault
SegmentFault 移知
移知 安芯教育
安芯教育 InfoQ
InfoQ 深圳湾
深圳湾 脑极体
脑极体 甲子光年
甲子光年 半导体行业观察
半导体行业观察 爱集微
爱集微 E 企研究院
E 企研究院 CSDN
CSDN 全志在线
全志在线 智东西
智东西















